OpenRefine 2024 User Survey Results
Every two years, OpenRefine conducts an extensive survey among its users. Our sixth edition was live in August-October 2024. The 2024 user survey included a feature prioritization poll (see the results) and questions regarding our new mission, vision, and value statement (see the results). This year, we received 226 answers. This post focuses on the survey analysis.
You can refer to the previous year editions: 2012, 2014, 2018, 2020 and 2022. This year, we did not include the questions "How would you rate your skills using OpenRefine?" and "How long have you been using OpenRefine?". We will use them to correlate with other answers in a later analysis. You can download the anonymized answers here.
So now, let's dive in.
Who are you?
OpenRefine Communities
Overall, our largest communities remain stable, with Researcher (38.50%) becoming the largest, followed by Librarian (34.01%), Data Science (25.66%), Wikimedian (25.66%), and GLAM (22.57%) close behind.
This year, we introduced OpenSource Intelligence (OSINT) and Civic Tech as default options. We had information that OpenRefine was used by those communities, and we wanted to find out to what extent. We have 10 respondents from CiviTech users and 6 working on OSINT. So, while they are present and align with our vision of building a more informed world where working with data is easy and engaging, they do not represent the majority of our users.
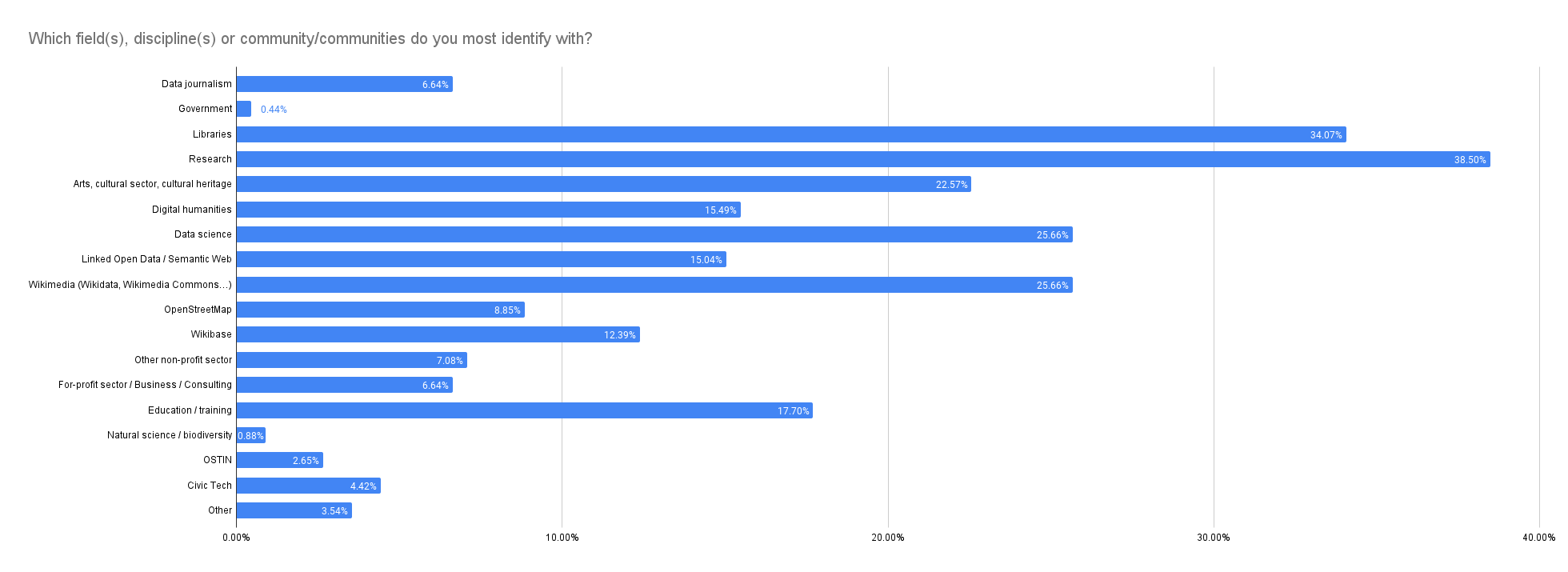
Change in methodology: In this question, an individual may identify with multiple communities. In the previous year, we normalized the results based on the total number of communities selected. In 2024, 226 respondents identified, on average, with 2.48 communities (we received 561 selections). With our previous approach, we would have represented CiviTech as 1.78% of our user base (10 divided by 561). This year, we computed the results based on the total number of respondents (226), which allows us to say that 4.42% of our users identify as CiviTech users.
Professional Usage
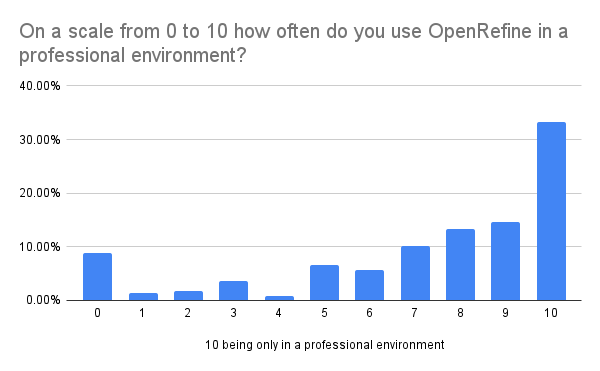
Last year, 85.1% of respondents indicated that they primarily use OpenRefine for work. This year, we provided a scale to measure the proportion of their usage in a professional environment. The results are consistent with those from 2022, as 71% of respondents reported using OpenRefine primarily in a professional setting (at least 70% of the time).
Languages used
The question "In which languages do you use OpenRefine (both its interface and the datasets you work with)?" reveals the diversity of our community, with 37 languages reported. English is less dominant than it was two years ago, dropping from 64.1% to 55.7% this year. German, French, and Spanish remain the top three other languages, followed by a long tail of 33 other languages.
Interestingly, 40.27% of users reported interacting in multiple languages. In our next survey, it may be beneficial to separate questions about the user interface from the dataset language.

Ovall Satisfaction and Net Promoter Score
In 2022, we asked our users to provide a general score for the software for the first time. On average, respondents rated OpenRefine a solid 8 out of 10!
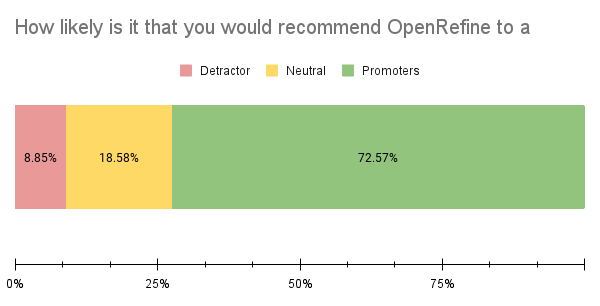
This year, instead of requesting a numerical score, we calculated a Net Promoter Score (NPS), which ranges from -100 to +100. OpenRefine achieved a total score of 63.72. Among respondents, 72.57% were promoters (those who scored nine or ten) and would recommend OpenRefine, while only 8.85% were detractors (those who scored six or below).
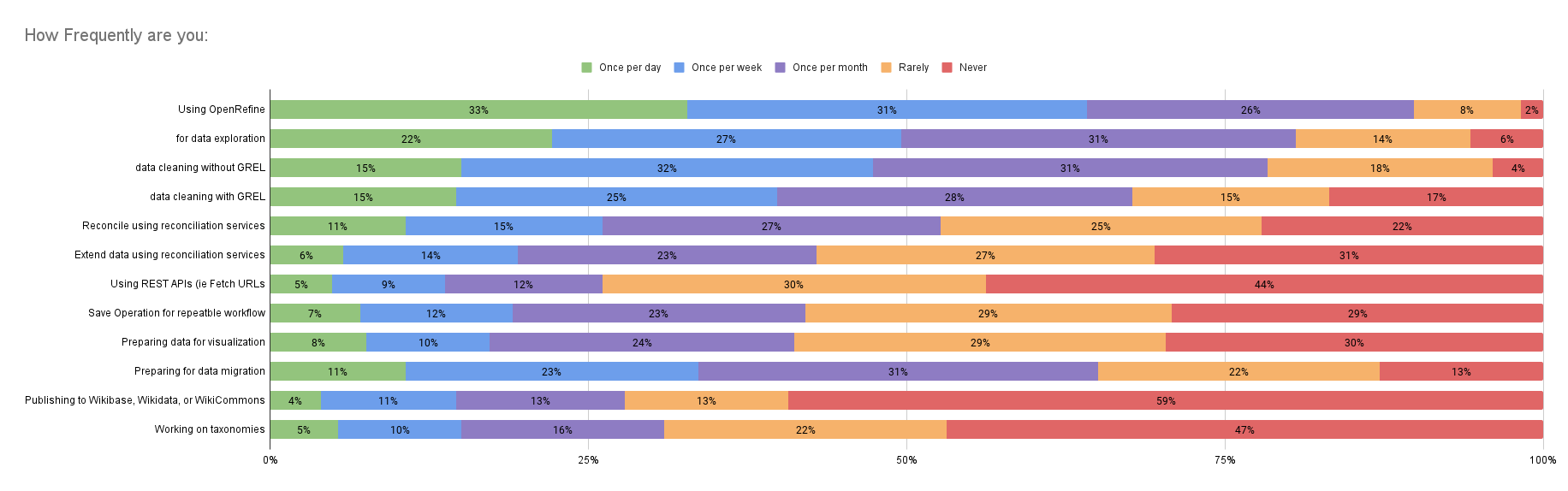
Feature Usage
When comparing this year's results to last year's, we found a significant increase in users who reported using OpenRefine daily, rising from approximately 10% to 33%. This raises the question of whether the change in survey methodology contributed to this increase.
Overall, we delved into greater detail this year than in the previous survey and assessed the frequency of use for different features and use cases of OpenRefine. This question format allows us to create more refined user personas by combining usage frequency with responses to other questions to help answer some design or product decisions.
Some interesting findings include that 53% of users accessed a reconciliation service at least once a month, and 41% of users published to Wikibase, Wikidata, or Wikimedia Commons.
The anomyized answer is available here if you want to investigate further (if you do, please share your findings on the forum, we would love to read them).
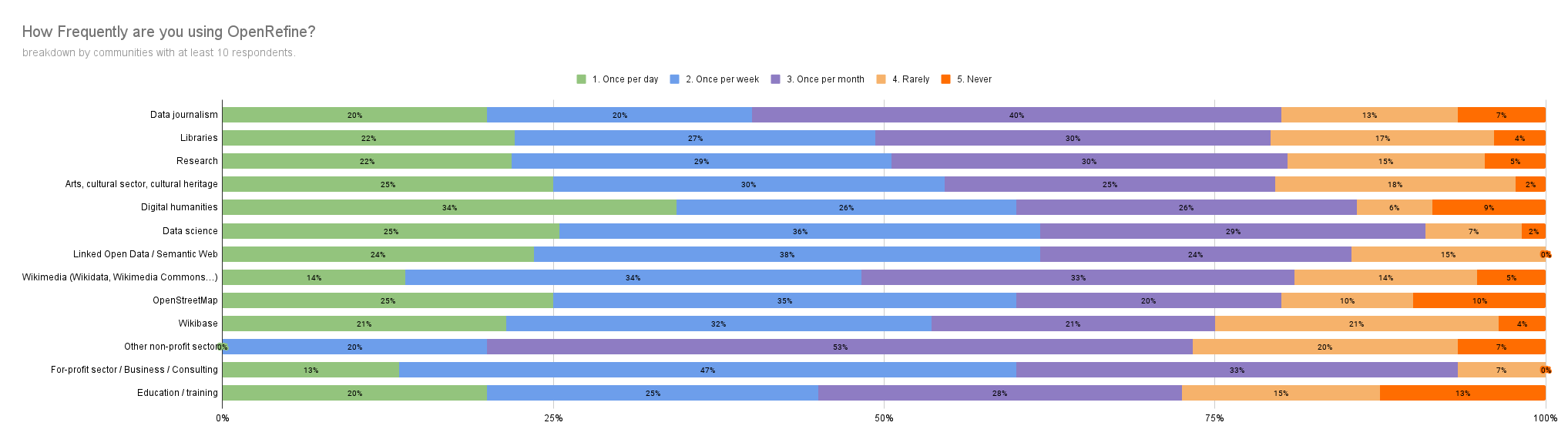
Frequency of usage per community
We conducted a more in-depth analysis by correlating the frequency of OpenRefine usage with the communities identified by users (only communities with at least 10 respondents were included in this analysis). Our findings indicate that Humanities, Data Science, and the Semantic Web have the highest regular usage, with over 60% of respondents using OpenRefine at least once a week.
The survey also confirmed anecdotal feedback: while OpenRefine is important for Wikimedians, they use it less frequently compared to other communities. Only 14% reported using it daily, compared to 33% of our total user base.
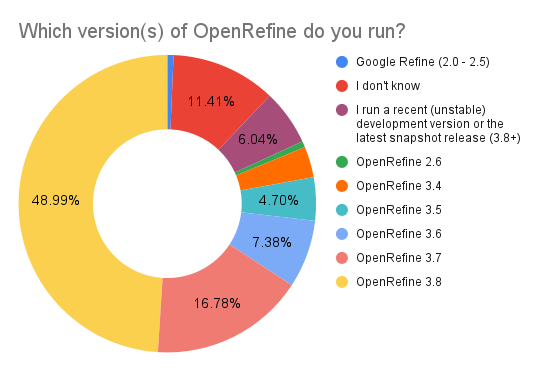
OpenRefine installation and configuration
Close to 49% of respondents currently run OpenRefine 3.8, the current stable release, while 6.04% use a development version. Additionally, 22.12% of users run an older version, consistent with the 23.8% of users running a legacy version in 2022.
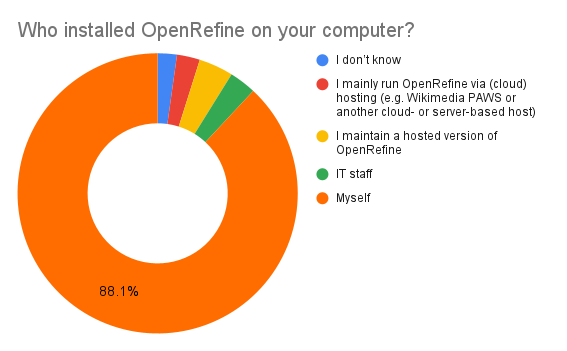
88% of users installed OpenRefine themselves. In contrast, 3% of installations were carried out by IT staff, and 6.64% of users utilize a hosted version (2.65% of users maintain a hosted version, while 3.98% use it). The percentage of users running or maintaining a cloud version has decreased compared to 2022, when 5% were cloud users and 5% were maintainers.
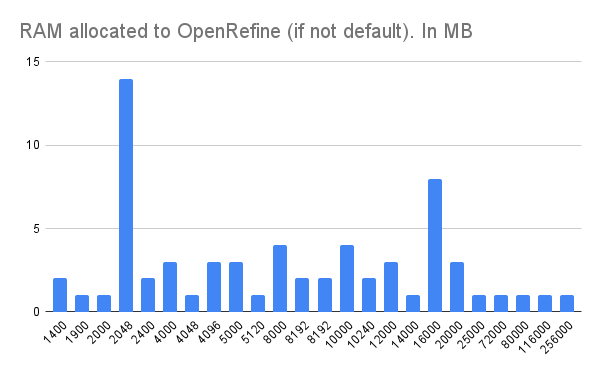
RAM allocation
In 2024, we introduced a new question to understand how much RAM users have allocated to OpenRefine. The larger the dataset (in terms of rows and columns), the more RAM OpenRefine will need to process it. This question serves as a proxy to evaluate how scalable OpenRefine should be and the technical savvy of our users since increasing the RAM required advanced configurations.
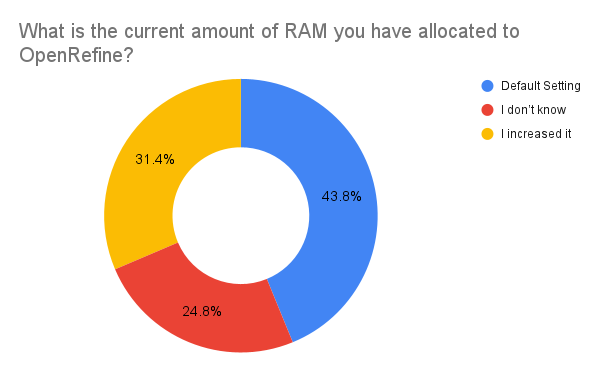
Only 24.8% of users allocated more RAM, while 43% used the default setting. Among users who modified the RAM, allocations varied widely, ranging from 1,400 MB (the current default) to 256,000 MB (or a whopping 256 GB of RAM). Most users, however, adjusted their settings to between 2,048 MB and 16 GB.
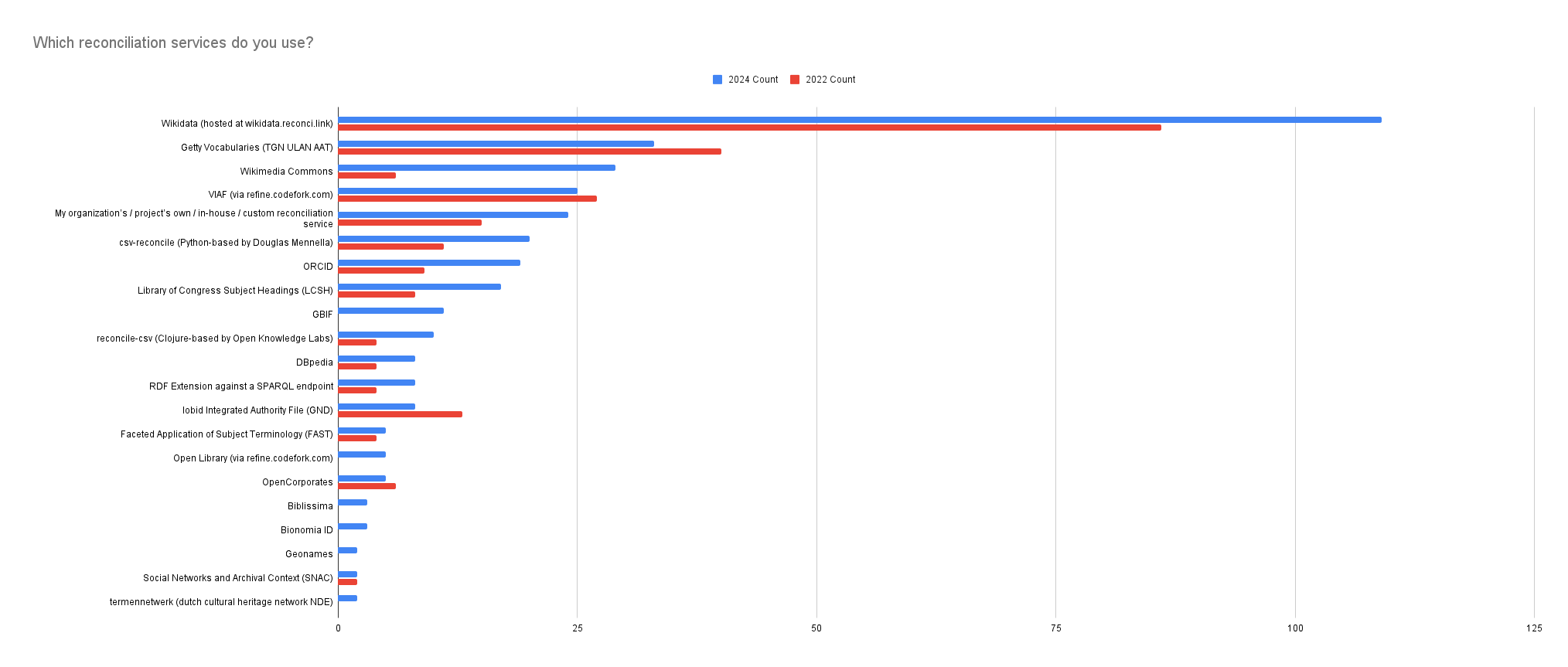
Reconciliation Services Usage
In 2024, reconciliation services continued to rise in popularity, with over 30 endpoints reported. OpenRefine comes with Wikidata as the default reconciliation server, which remains the most used, boasting 109 users (or 43.95% of OpenRefine users). The Commons extension increased in popularity, growing from 6 users in 2022 to 29 users in 2024, and became the second most used endpoint.
The Getty endpoints and VIAF also maintained their popularity. The internal reconciliation service also increased from 15 users in 2022 to 24 users in 2024.
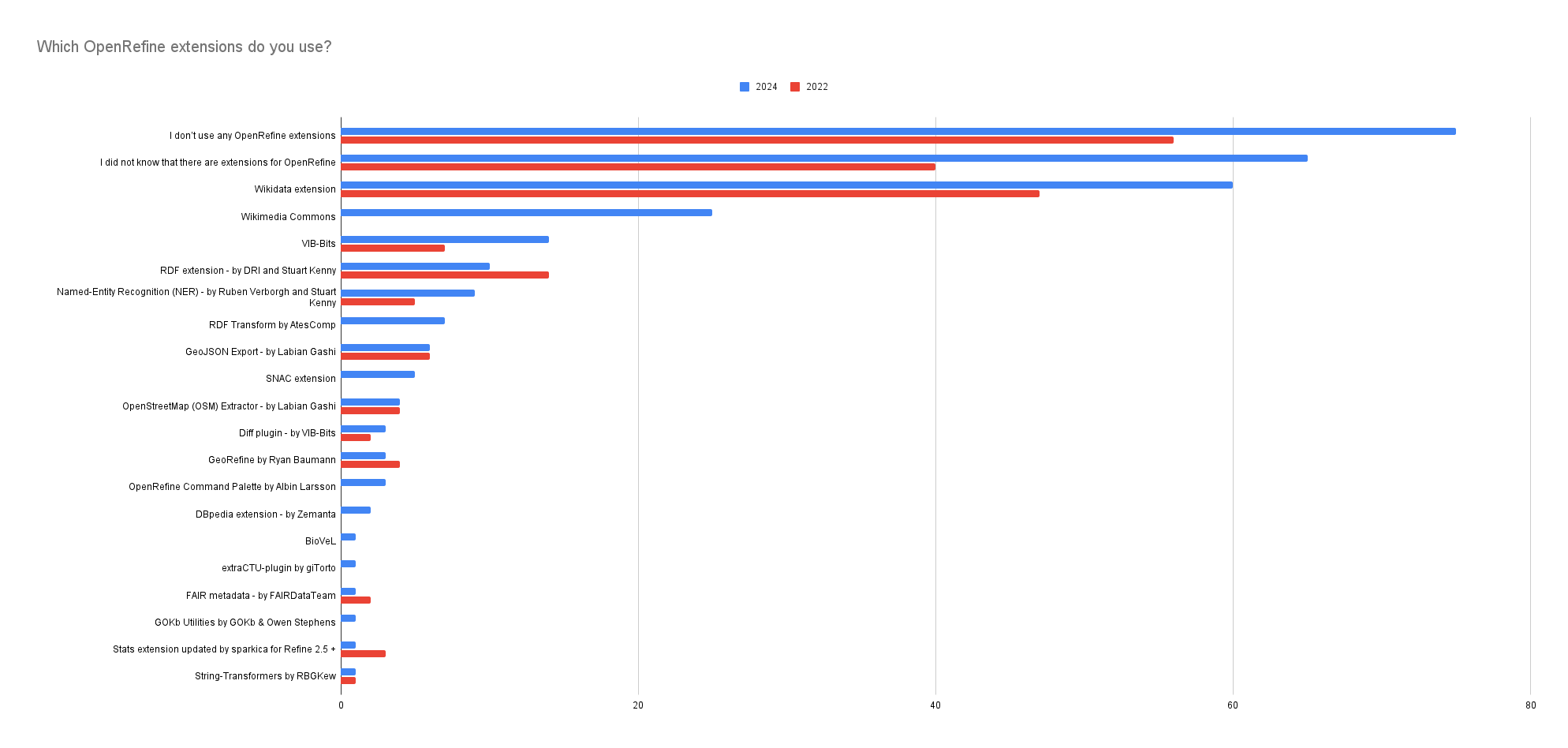
Extension and Plugin usage
47% of respondents are unaware of extensions or do not use any (compared to 50% in 2022). Wikidata is utilized by 20% of respondents (down from 26% in 2022), while the Wikimedia Commons extension is used by 8.42%, making them the two most popular extensions. The two RDF extensions together are used by 5.72% of users, followed by the VIB-BITS extension at 4.71% and the NER extension at 3.03%.
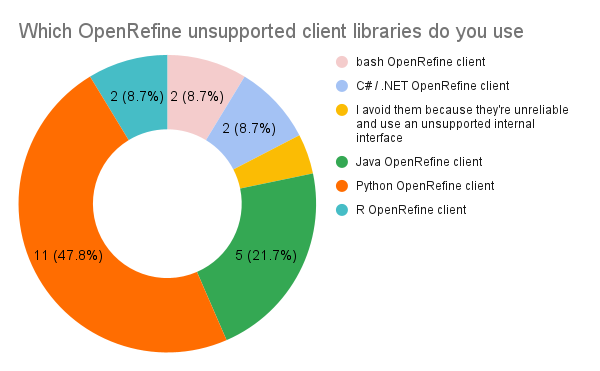
Only 12.39% of the respondents use a third-party library to automate OpenRefine tasks. The Python client is the most popular one, with 47% usage.
Why are you using OpenRefine?
When asked about the features that led them to choose OpenRefine over other tools, respondents indicated that
- Faceting, clustering, and cleaning of messy data remain the top features. Users reported that OpenRefine offers a user-friendly interface with visual previews and an approachable learning curve compared to Python, R, or SQL scripting.
- Tight integration with tools like APIs, and Wikibase, as well as the support of Reconciliation Services, is highly valued, especially for tasks like linking data standards or updating Wikidata, Wikibase, or Wikimedia Commons.
- Users praise its ability to process large datasets efficiently, something tools like Excel struggle with.
- Users value the flexibility with custom export formats and operation history for repeatable workflows.
- Free availability, good documentation and community-driven development resonate strongly with users.
What can be improved?
This year's questions about improving OpenRefine were addressed in a feature prioritization survey, and the results are available on the forum. More generic improvement requests include:
- Reducing the learning curve when using advanced features, particularly for reconciliation and data merging.
- Improving the UI/UX, which involves better schema configuration and larger preview windows.
- Providing more intuitive installation and configuration options, better plugin management, and highlighting available reconciliation services.
In closing ...
... some kind words we received in the open comment question:
A Libraries, Arts cultural sector cultural heritage, Digital humanities, Wikibase user:
OpenRefine makes a lot of cleanup and standardization tasks much easier. If it wasn't available I would cry at my desk. :)
A Digital humanities user
I can't imagine my life and thought process without OR...
A Libraries and Education / training user:
Openrefine is a lifesaver in many ways and I'm always delighted to learn new ways to use it.
A Libraries and Education / training user:
OpenRefine is the best tool for my data needs. I am so that this tool exists and is still maintained.
A Research and Academic, Wikimedia (Wikidata Wikimedia Commons…), Education / training user:
keep up the good work! OpenRefine is amazing and I would not be doing this work without it
A Libraries, Research and Academic, Arts cultural sector cultural heritage user:
If I need to do anything more than basic Excel functions, I usually go to OR. I'd be lost without it
An Arts cultural sector cultural heritage user:
It's the easiest way by far to do the work I need to do. Without it I would work in a combination of vim, awk and other bash utilities