Exploring facets
Overview
Facets are one of OpenRefine’s strongest features - that’s where the diamond logo comes from!
Faceting allows you to look for patterns and trends. Facets are essentially aspects or angles of data variance in a given column. For example, if you had survey data where respondents indicated one of five responses from “Strongly agree” to “Strongly disagree,” those five responses make up a text facet, showing how many people selected each option.
Faceted browsing gives you a big-picture look at your data (do they agree or disagree?) and also allows you to filter down to a specific subset to explore it more (what do people who disagree say in other responses?).
Typically, you create a facet on a particular column. That facet selection appears on the left, in the Facet/Filter tab, and you can click on a displayed facet to view all the records that match. You can also “exclude” the facet, to view every record that does not match, and you can select more than one facet by clicking “include.”
An example
You can learn about facets and filtering with the following example. You can copy the following table and paste it using the method of starting a project if you would like to try it yourself. Check the "Attempt to parse cell text into numbers" option so that you can use numeric faceting.
We collected a list of the 10 most populous cities from Wikidata, using an example query of theirs. We removed the GPS coordinates and added the country.
| cityLabel | population | countryLabel |
|---|---|---|
| Shanghai | 23390000 | People's Republic of China |
| Beijing | 21710000 | People's Republic of China |
| Lagos | 21324000 | Nigeria |
| Dhaka | 16800000 | Bangladesh |
| Mumbai | 15414288 | India |
| Istanbul | 14657434 | Turkey |
| Tokyo | 13942856 | Japan |
| Tianjin | 13245000 | People's Republic of China |
| Guangzhou | 13080500 | People's Republic of China |
| São Paulo | 12106920 | Brazil |
If we want to see which countries have the most populous cities, we can create a text facet on the “countryLabel” column and OpenRefine will generate a list of all the different strings used in these cells.
We will see in the sidebar that the countries identified are displayed, along with the number of matches (the “count”). We can sort this list alphabetically or by the count. If you sort by count at the top of the facet window, you’ll learn which countries hold the most populous cities.
| Facet | Count |
|---|---|
| People's Republic of China | 4 |
| Bangladesh | 1 |
| Brazil | 1 |
| India | 1 |
| Japan | 1 |
| Nigeria | 1 |
| Turkey | 1 |
If we want to learn more about a particular country, we can click on its appearance in the facet sidebar. This narrows our dataset down temporarily to only rows matching that facet.
You’ll see the “10 rows” indicator change to “4 matching rows (10 total)” if you click on “People’s Republic of China”. In the data grid, you’ll see fewer rows: only the ones matching your current filter. Each row will maintain its original numbering, though - in this case, rows #1, 2, and 8.
If you want to go back to the original dataset, click or the small “exclude” text next to the facet. If you want to view the most populous cities in both China and India, click “include” next to each facet. Now you’ll see 5 rows - #1, 2, 5, 8, 9.
We can also explore our data using the population information. In this case, because population is a number, we can create a numeric facet. This will give us the ability to explore by range rather than by exact matching values.
With the numeric facet, we are given a scale from the smallest to the largest value in the column. We can drag the range minimum and maximum to narrow the results. In this case, if we narrow down to only cities with more than 20 million in population, we get 3 matching rows out of the original 10.
When you look back at the text facet display of country names, you should see a smaller list with a reduced count: OpenRefine is now displaying the facets of the 3 matching rows, not the total dataset of 10 rows.
We can combine these facets - say, by narrowing to only the Chinese cities with populations greater than 20 million - simply by clicking in both. You should see 2 matching rows for both these criteria.
Things to know about facets
When you have facets applied, you will see “matching rows” in the project grid header. If you click and copy your data out of OpenRefine while facets are active, many of the exporting options will only export the matching rows, not all the rows in your project.
OpenRefine has several default facets, which you’ll learn about below. The most powerful facets are the ones designed by you - custom facets, written using expressions to transform the data behind the scenes and help you narrow down to precisely what you’re looking for.
Facets are not saved in the project along with the data. But you can save a link to the current state of the application. Find the next to the project’s name.
You can modify any facet expression by clicking the “change” button to the right of the column name in the facet sidebar.
Facet boxes that appear in the sidebar can be resized and rearranged. You can drag and drop the title bar of each box to reorder them, and drag on the bottom bar of text facet boxes.
Certain operations don't respect facet settings. If you perform any of the following operations while filtering your data with a facet, the operation will apply to all relevant data, columns, and/or rows in the table, not just those which you have filtered with the facet:
- Moving, Removing, Renaming, or Reordering a column
- Splitting or Joining multi-valued cells
- Reordering of rows
- Transposition (columns to rows, rows to columns, and columnization by key/value columns)
Text facet
A text facet can be generated on any column with the “text” data type. Select the column dropdown and go to → . The created facet will be sorted alphabetically, and can be sorted by count.
A text facet is very simple: it takes the total contents of the cells of the column in question and matches them up. It does no guessing about typos or near-matches.
You can edit any entry that appears in the facet display, by hovering over the facet and clicking the “edit” button that appears. You can then type in a new value manually. This will mass-edit every identical cell in the column. This is a great way to fix typos, whitespace, and other issues that may be affecting the way facets appear. You can also automate the cleanup of facets by using clustering: a “Cluster” button is displayed within the facet window. It may be most efficient to cluster cells to one value, and then mass-edit that value to your desired string within the clustering operation window.
Each text facet shows up to 2,000 choices by default. You can increase this limit on the Preferences screen if you need to, which may slow down your browser. If your applied facet has more choices than the current limit, you'll be offered the option to increase the limit, which will permanently edit that preference for you.
The choices and counts displayed in each facet can be copied as tab-separated values. To do so, click on the "X choices" link near the top left corner of the facet. This can be useful to generate small summary tables of your data.
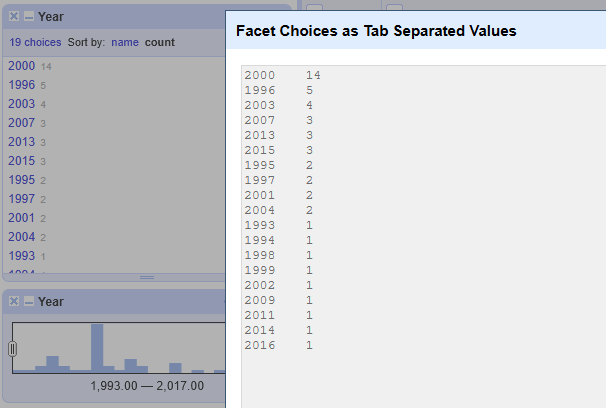
Numeric facet

Whereas a text facet groups unique text values into groups, a numeric facet sorts numbers by their range - smallest to biggest. This displays visually as a histogram, and allows you to set a custom facet within that range. You can drag the minimum and maximum range markers to set a range. OpenRefine snaps to some basic equal-sized divisions - 19 in the example set above.
You will be offered the option to include blank, non-numeric, and error values in your numeric visualization; these will appear in the visual range as “0” values.
You can create a text facet on numeric data, which will treat each entry as a string. This can be useful if you wish, for example, to manually include facets instead of selecting a range, or sort by count, or copy that count.
As mentioned in the overview, facets can be modified or customized by GREL expressions in many ways. For example, to facet by clusters of row numbers with row.index/100 or better visualizing numbers greater than 1000 with max(row.index, 1000).
Timeline facet

Much like a numeric facet, a timeline facet will display as a small histogram with the values sorted: in this case, chronologically. A timeline facet only works on cells formatted as the “date” data type.
The facet appears with a count of blank cells and those with errors, which can help you analyze whether your date cells are correctly converted.
Scatterplot facet
A scatterplot is a visual representation of two related sets of numeric data.
You have the option to generate linear scatterplots (where the X and Y axes show continuous increases) or logarithmic scatterplots (where the X and Y axes show exponential or scaled increases). You can also rotate the plot by 45 degrees in either direction, and you can choose the size of the dot indicating a datapoint. You can make these choices in both the preview and in the facet display.
A scatterplot facet can be generated on any column. You require two or more number columns to generate scatterplots. Selecting → will create a preview of data plotted from every number-formatted column in your dataset, comparing every column against every other column. Each scatterplot will show in its own square, allowing you to choose which data comparison you would like to analyze further. You can control which columns are on the X and Y axes by rearranging the columns in your dataset.

When you click on your desired square, that two-column comparison will appear in the facets sidebar. From here, you can drag your mouse to draw a rectangle inside the scatterplot, which will narrow down to just the rows matching the points plotted inside that rectangle (as shown by the rectangle inside the square in the image above). This rectangle can be resized by dragging any of the four edges. To draw a new rectangle, simply click and drag your mouse again. To add more scatterplots to the facet sidebar, re-run this process and select a different square.
If you have multiple facets applied, plotted points in your scatterplot displays will be greyed out if they are not part of the current matching data subset. If the rectangle you have drawn within a scatterplot display only includes grey dots, you will see no matching rows.
If you would like to export a scatterplot, OpenRefine will open a new tab with a generated PNG file that you can save.
Custom text facet
You may want to explore your textual data with modifications that aren't permanent. Creating custom text facets will load your column into memory, transform the data temporarily, and store those transformations inside the facet.
You can also use custom text facets to analyze numerical data, such as by analyzing a number as a string, or by creating a test that will return “true” and “false” as values.
Clicking on → will bring up an expressions window where you can enter in a GREL, Jython, or Clojure expression to modify how the facet works.
A custom text facet operates just like a text facet by default. Unlike a text facet, however, you cannot click “edit” on the facets that appear in the sidebar and change the matching cells in your dataset - because what they display is modified, not the original entries.
For example, you may wish to analyze only the first word in a text field - perhaps the first name in a column of “[First Name] [Last Name]” entries. In this case, you can tell OpenRefine to facet only on the information that comes before the first space:
value.split(" ")[0]
In this case, split() is creating an array of text strings based on every space in the cells ["Firstname", "Lastname"]. Because arrays number their entries starting with 0, we want the first value, so we ask for [0]. (Assuming the first name is one word, not something like “Mary Anne.”) We can do the same splitting and ask for the last name with
value.split(" ")[1]
You may want to create a facet that references several columns. For example, let’s say you have two columns, “First Name” and “Last Name”, and you want out how many people have the same initial letter for both names (e.g., Marilyn Monroe, Steven Segal). To do so, create a custom text facet on either column and enter the expression
cells["First Name"].value[0] == cells["Last Name"].value[0]
That expression will look for the first letter (the character at index 0) of each entry and compare them. Then it will facet your rows into “true” and “false.”
You can learn more about text-modification functions on the Expressions page.
Custom numeric facet
You may want to explore your numerical data with modifications that aren't permanent. You can also use custom numeric facets to analyze textual data, such as by getting the length of text strings (with value.length()), or by analyzing it as though it were formatted as numbers (with toNumber(value)).
If you would like to build your own version of a numeric facet, you can use the option. Clicking on → will bring up an expressions window where you can enter in a GREL, Jython, or Clojure expression to modify how the facet works. A custom numeric facet operates just like a numeric facet by default.
For example, you may wish to create a numeric facet that rounds your value to the nearest integer, enter
round(value)
If you have two columns of numbers and for each row you wish to create a numeric facet only on the larger of the two, enter
max(cells["Column1"].value, cells["Column2"].value)
If the numeric values in a column are drawn from a power law distribution, then it's better to group them by their logs:
value.log()
If the values are periodic you could take the modulus by the period to understand if there's a pattern:
mod(value, 7)
You can learn more about numeric-modification functions on the Expressions page.
Customized facets
Customized facets have been added to expand the number of default facets users can apply with a single click. They represent some common and useful functions you shouldn’t have to work out using an expression.
All facets that display in the Facet/Filter tab can be edited by clicking on the “change” button to the right of the column title. This brings up the expressions window that will allow you to modify and preview the expression being used.
Word facet
A is a simple version of a text facet: it splits up the content of the cells based on spaces, and outputs each character string as a facet:
value.split(" ")
This can be useful for exploring the language used in a corpus, looking for common first and last names or titles, or seeing what’s in multi-valued cells you don’t wish to split up.
Word facet is case-sensitive and only splits by spaces, not by line breaks or other natural divisions.
Duplicates facet
A will return only rows that have non-unique values in the column you’ve selected. It will create a facet of “true” and “false” values - true being cells that are not unique, and “false” being cells that are. The actual expression being used is
facetCount(value, 'value', '[Column]') > 1
Duplicates facets are case-sensitive and you may wish to filter out things like leading and trailing whitespace or other hard-to-see issues. You can modify the facet expression, for example, with:
facetCount(trim(toLowercase(value)), 'trim(toLowercase(value))', 'cityLabel') > 1
Numeric log facet
Logarithmic scales reduce wide-ranging quantities to more compact and manageable ranges. A log transformation can be used to make highly skewed distributions less skewed. If your numerical data is unevenly distributed (say, lots of values in one range, and then a long tail extending off into different magnitudes), a can represent that range better than a simple numeric facet. It will break these values down into more navigable segments than the buckets of a numeric facet. This facet can make patterns in your data more visible. OpenRefine uses a base-10 log, the “common logarithm.”
For example, we can look at this data about the body weight of various mammals:
| Species | BodyWeight (kg) |
|---|---|
| Newborn_Human | 3.2 |
| Adult_Human | 73 |
| Pithecanthropus_Man | 70 |
| Squirrel | 0.8 |
| Hamster | 0.15 |
| Chimpanzee | 50 |
| Rabbit | 1.4 |
| Dog_(Beagle) | 10 |
| Cat | 4.5 |
| Rat | 0.4 |
| Sperm_Whale | 35000 |
| Turtle | 3 |
| Alligator | 270 |
Most values will be clustered in the 0-100 range, but 35,000 is many magnitudes above that. A numeric facet will create 36 equal buckets of 1,000 each - containing almost all the cells in the first bucket. A numeric log facet will instead display the data more evenly across the visual range.

A 1-bounded numeric log facet can be used if you'd like to exclude all the values below 1 (including zero and negative numbers).
Text-length facet
The returns a numerical value for each cell and plots it on a numeric facet chart. The expression used is
value.length()
This can be useful to, for example, look for values that did not successfully split on an earlier split operation, or to validate that data is a certain expected length (such as whether a date in YYYY/MM/DD is eight to ten characters).
You can also employ a that allows you to navigate more easily a wide range of string lengths. This can be useful in the case of web-scraping, where lots of textual data is loaded into single cells and needs to be parsed out.
Unicode character-code facet

The Unicode facet identifies and returns Unicode decimal values. It generates a list of the Unicode numerical values of each character used in each text cell, which allows you to narrow down and search for special characters, punctuation, and other data formatting issues.
This facet creates a numerical chart, which offers you the ability to narrow down to a range of numbers. For example, lowercase characters are numbers 97-122, uppercase characters are numbers 65-90, and numerical digits are numbers 48-57.
Facet by error
An error is a data type created by OpenRefine in the process of transforming data. For example, say you had converted a column to the number data type. If one cell had text characters in it, OpenRefine could either output the original text string unchanged or output an error. If you allow errors to be created, you can facet by them later to search for them and fix them.
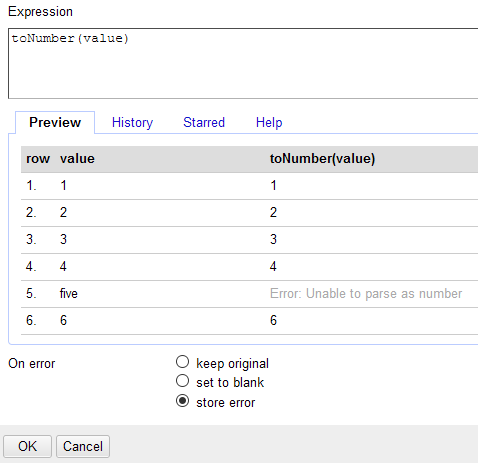
To store errors in cells, ensure that you have store error selected for the “On error” option in the expressions window.
Facet by null, empty, or blank
Any column can be faceted for null and/or empty cells. These can help you find cells where you want to manually enter content.
“Blank” means both null values and empty values. All three facets will generate “true” and “false” facets, “true” being blank.
An empty cell is a cell that is set to contain a string, but doesn’t have any characters in it (a zero-length string). This can be left over from an operation that removed characters, or from manually editing a cell and deleting its contents.
Facet by star or flag
Stars and flags offer you the opportunity to mark specific rows for yourself for later focus. Stars and flags persist through closing and opening your project, and thus can provide a different function than using a permalink to persist your facets. Stars and flags can be used in any way you want, although they are designed to help you flag errors and star rows of particular importance.
You can manually star or flag rows simply by clicking on the icons to the left of each row.
You can also apply stars or flags to all matching rows by using the dropdown menu (on the first column) and selecting → or . This will create “true” and “false” facets in the Facet/Filter. These operations will modify all matching rows in your current subset. You can unstar or unflag them as well.
You may wish to create a custom subset of your data through a series of separate faceting activities (rather than successively narrowing down with multiple facets applied). For example, you may wish to:
- apply a facet
- star all the matching rows
- remove that facet
- apply another, unrelated facet
- star all the new matching rows (which will not modify already-starred rows)
- remove that facet
- and then work with all of the cumulative starred rows.
You can also create a text facet on any column with the expression row.starred or row.flagged.
Text filter
Filters allow you to narrow down your data based on whether a given column includes a text string.
When you choose a box appears in the Facet/Filter tab that allows you to enter in text. Matching rows will narrow dynamically with every character you enter. You can set the search to be case-sensitive or not, and you can use this box to enter in a regular expression.
For example, you can enter in “side” as a text filter, and it will return all cells in that column containing “side,” “sideways,” “offside,” etc.
The text filter field supports regular expressions. For example, you can employ a regular expression to view all properly-formatted emails:
([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9\-\.]+)\.([a-zA-Z0-9\-]{2,15})
You can press “invert” on this facet to then see blank cells or invalid email addresses.
This filter works differently than facets because it is always active as long as it appears in the sidebar. If you “reset” it, you will delete all the text or expression you have entered.
You can apply multiple text filters in succession, which will successively narrow your data subset. This can be useful if you apply multiple inverted filters, such as to filter out all rows that respond “yes” or “maybe” and only look at the remaining responses.