Running OpenRefine
Starting and exiting
OpenRefine does not require internet access to run its basic functions. Once you download and install it, it runs as a small web server on your own computer, and you access that local web server by using your browser.
You will see a command line window open when you run OpenRefine. Ignore that window while you work on datasets in your browser.
No matter how you start OpenRefine, it will load its interface in your computer’s default browser. If you would like to use another browser instead, start OpenRefine and then point your chosen browser at the home screen: http://127.0.0.1:3333/.
OpenRefine works best on browsers based on WebKit, such as:
We are aware of some minor rendering and performance issues on other browsers such as Firefox. We don't support Internet Explorer.
You can view and work on multiple projects at the same time by simply having multiple tabs or browser windows open. From the screen, you can right-click on project names and open them in new tabs or windows.
- Windows
- Mac
- Linux
With openrefine.exe
You can run OpenRefine by double-clicking openrefine.exe or calling it from the command line.
If you want to modify the way openrefine.exe opens, you can edit the openrefine.l4j.ini file.
With refine.bat
On Windows, OpenRefine can also be run by using the file refine.bat in the program directory. If you start OpenRefine using refine.bat, you can do so by opening the file itself, or by calling it from the command line.
If you call refine.bat from the command line, you can start OpenRefine with modifications.
If you want to modify the way refine.bat opens through double-clicking or using a shortcut, you can edit the refine.ini file.
Exiting
To exit OpenRefine, close all the browser tabs or windows, then navigate to the command line window. To close this window and ensure OpenRefine exits properly, hold down Control and press C on your keyboard. This will save any last changes to your projects.
You can find OpenRefine in your Applications folder, or you can open it using Terminal.
To run OpenRefine using Terminal:
- Find the OpenRefine application / icon in Finder
- Control-click on the icon and select “Show Package Contents” from the context menu
- This should open a new Finder menu: navigate into the “MacOS” folder
- Control-click on “JavaAppLauncher”
- Choose “Open With” from the menu, and select “Terminal.”
To exit, close all your OpenRefine browser tabs, go back to the terminal window and press Command and Q to close it down.
If you are using an older version of OpenRefine or are on an older version of MacOS, check our Wiki for solutions to problems with MacOS.
Use a terminal to launch OpenRefine. First, navigate to the installation folder. Then call the program:
cd openrefine-3.4.1
./refine
This will start OpenRefine and open your browser to the home screen.
To exit, close all the browser tabs, and then press control and C in the terminal window.
“Error: Could not find the ‘java’ executable at ‘’, are you sure your JAVA_HOME environment variable is pointing to a proper java installation?”
If you see this error, you need to install and configure a JDK package, including setting up JAVA_HOME.
Troubleshooting
If you are having problems connecting to OpenRefine with your browser, check our Wiki for information about browser settings and operating-system issues.
Starting with modifications
When you run OpenRefine from a command line, you can change a number of default settings.
- Windows
- Mac
- Linux
On Windows, use a slash:
C:>refine /i 127.0.0.2 /p 3334
Get a list of all the commands with refine /?.
| Command | Use | Syntax example |
|---|---|---|
| /w | Path to the webapp | refine /w /path/to/openrefine |
| /m | Memory maximum heap | refine /m 6000M |
| /p | Port | refine /p 3334 |
| /i | Interface (IP address, or IP and port) | refine /i 127.0.0.2:3334 |
| /H | HTTP host to expect on incoming requests | refine /H openrefine.internal |
| /d | Path to the workspace | refine /d /where/you/want/the/workspace |
| /v | Verbosity (from low to high: error,warn,info,debug,trace) | refine /v info |
| /x | Additional Java configuration parameters (see Java documentation) | refine /x refine.autosave=5 refine /x refine.data_dir=/ refine /x refine.development=false refine /x refine.headless=false refine /x refine.host=127.0.0.1 refine /x refine.port=3333 refine /x refine.webapp=main/webapp refine /x refine.display.new.version.notice=true |
| /debug | Enable debugging (on port 8000) | refine /d |
| /jmx | Enable JMX monitoring for Jconsole and JvisualVM | refine /x |
You cannot start the Mac version with modifications using Terminal, but you can modify the way the application starts with settings within files.
To see the full list of command-line options, run ./refine -h.
| Command | Use | Syntax example |
|---|---|---|
| -w | Path to the webapp | ./refine -w /path/to/openrefine |
| -d | Path to the workspace | ./refine -d /where/you/want/the/workspace |
| -m | Memory maximum heap | ./refine -m 6000M |
| -p | Port | ./refine -p 3334 |
| -i | Interface (IP address, or IP and port) | ./refine -i 127.0.0.2:3334 |
| -H | HTTP host to expect on incoming requests | ./refine -H openrefine.internal |
| -k | Add a Google API key | ./refine -k YOUR_API_KEY |
| -v | Verbosity (from low to high: error,warn,info,debug,trace) | ./refine -v info |
| -x | Additional Java configuration parameters (see Java documentation) | ./refine -x refine.autosave=5 ./refine -x refine.data_dir=/ ./refine -x refine.development=false ./refine -x refine.headless=false ./refine -x refine.host=127.0.0.1 ./refine -x refine.port=3333 ./refine -x refine.webapp=main/webapp ./refine -x refine.display.new.version.notice=true |
| --debug | Enable debugging (on port 8000) | ./refine --debug |
| --jmx | Enable JMX monitoring for Jconsole and JvisualVM | ./refine --jmx |
Modifications set within files
On Windows, you can modify the way openrefine.exe runs by editing openrefine.l4j.ini; you can modify the way refine.bat runs by editing refine.ini.
You can modify the Mac application by editing info.plist.
On Linux, you can edit refine.ini.
Some settings, such as changing memory allocations, are already set inside these files, and all you have to do is change the values. Some lines need to be un-commented to work.
For example, inside refine.ini, you should see:
no_proxy="localhost,127.0.0.1"
#REFINE_PORT=3334
#REFINE_HOST=127.0.0.1
#REFINE_WEBAPP=main\webapp
# Memory and max form size allocations
#REFINE_MAX_FORM_CONTENT_SIZE=1048576
REFINE_MEMORY=1400M
# Set initial java heap space (default: 256M) for better performance with large datasets
REFINE_MIN_MEMORY=1400M
...
JVM preferences
Further modifications can be performed by using JVM preferences. These JVM preferences are different options and have different syntax than the key/value descriptions used on the command line.
Some of the most common keys (with their defaults) are:
| Description | Argument | Syntax example |
|---|---|---|
| The project autosave frequency | -Drefine.autosave | 5 [minutes] |
| The workspace director | -Drefine.data_dir | / |
| Development mode | -Drefine.development | false |
| Headless mode | -Drefine.headless | false |
| IP | -Drefine.host | 127.0.0.1 |
| Port | -Drefine.port | 3333 |
| The application folder | -Drefine.webapp | main/webapp |
| New version notice | -Drefine.display.new.version.notice | true |
The syntax is as follows:
- Windows
- Mac
- Linux
Locate the refine.l4j.ini file, and insert lines in this way:
-Drefine.port=3334
-Drefine.host=127.0.0.2
-Drefine.webapp=broker/core
-Dhttp.proxyHost=yourproxyhost
-Dhttp.proxyPort=8080
In refine.ini, use a similar syntax, but set multiple parameters within a single line starting with JAVA_OPTIONS=:
JAVA_OPTIONS=-Drefine.data_dir=C:\Users\user\Documents\OpenRefine\ -Drefine.port=3334
Locate the info.plist, and find the array element that follows the line
<key>JVMOptions</key>
Typically this looks something like:
<key>JVMOptions</key>
<array>
<string>-Xms256M</string>
<string>-Xmx1024M</string>
<string>-Drefine.version=2.6-beta.1</string>
<string>-Drefine.webapp=$APP_ROOT/Contents/Resource/webapp</string>
</array>
Add in values such as:
<key>JVMOptions</key>
<array>
<string>-Xms256M</string>
<string>-Xmx1024M</string>
<string>-Drefine.version=2.6-beta.1</string>
<string>-Drefine.webapp=$APP_ROOT/Contents/Resource/webapp</string>
<string>-Drefine.autosave=2</string>
<string>-Drefine.port=3334</string>
<string>-Dhttp.proxyHost=yourproxyhost</string>
<string>-Dhttp.proxyPort=8080</string>
</array>
Locate the refine.ini file, and add JAVA_OPTIONS= before the -Drefine.preference declaration. You can un-comment and edit the existing suggested lines, or add lines:
JAVA_OPTIONS=-Drefine.autosave=2
JAVA_OPTIONS=-Drefine.port=3334
JAVA_OPTIONS=-Drefine.data_dir=usr/lib/OpenRefineWorkspace
JAVA_OPTIONS=-Dhttp.proxyHost=yourproxyhost
JAVA_OPTIONS=-Dhttp.proxyPort=8080
Refer to the official Java documentation for more preferences that can be set.
The home screen
When you first launch OpenRefine, you will see a screen with a menu on the left hand side that includes , , , and . This is called the “home screen,” where you can manage your projects and general settings.
In the lower left-hand corner of the screen, you'll see , , and .
Language settings
From the home screen, look in the options to the left for . You can set your preferred interface language here. This language setting will persist until you change it again in the future. Languages are translated as a community effort; some languages are partially complete and default back to English where unfinished. Currently OpenRefine supports the following languages for 75% or more of the interface:
- Cebuano
- German
- English (UK)
- English (US)
- Spanish
- Filipino
- French
- Hebrew
- Magyar
- Italian
- Japanese (日本語)
- Portuguese (Brazil)
- Tagalog
- Chinese (简体中文)
To leave the Language Settings screen, click on the diamond “OpenRefine” logo.
We use Weblate to provide translations for the interface. You can check our profile on Weblate to see which languages are in the process of being supported. See our technical reference if you are interested in contributing translation work to make OpenRefine accessible to people in other languages.
Preferences
In the bottom left corner of the screen, look for . At this time you can set preferences using a key/value pair: that is, selecting one of the keys below and setting a value for it.
| Setting | Key | Value syntax | Default | Example | Version |
|---|---|---|---|---|---|
| Interface language | userLang | ISO 639-1 two-digit code | en | fr | — |
| Maximum facets | ui.browsing.listFacet.limit | Number | 2000 | 5000 | — |
| Timeout for Google Drive import | googleReadTimeOut | Number (microseconds) | 180000 | 500000 | — |
| Timeout for Google Drive authorization | googleConnectTimeOut | Number (microseconds) | 180000 | 500000 | — |
| Maximum lag for Wikibase edit retries | wikibase.upload.maxLag | Number (seconds) | 5 | 10 | — |
| Display of the reconciliation preview on hover | cell-ui.previewMatchedCells | Boolean | true | false | v3.2 |
| Values for the choice of the number of rows to display | ui.browsing.pageSize | Array of number (JSON) | [ 5, 10, 25, 50 ] | [ 100, 500, 1000 ] | v3.5 |
| Width of the panel for facets/history | ui.browsing.facetsHistoryPanelWidth | Number (pixel) | 300 | 500 | v3.5 |
| Default state of the reconciliation automatch option | ui.reconciliation.automatch | Boolean | true | false | v3.8 |
| Value of clusting choice limit | ui.clustering.choices.limit | Number | 5000 | 8000 | v3.8 |
To leave the Preferences screen, click on the diamond “OpenRefine” logo.
If the preference you’re looking for isn’t here, look at the options you can set from the command line or in an .ini file.
The project screen
The project screen (or work screen) is where you will spend most of your time once you have begun to work on a project. This is a quick walkthrough of the parts of the interface you should familiarize yourself with.
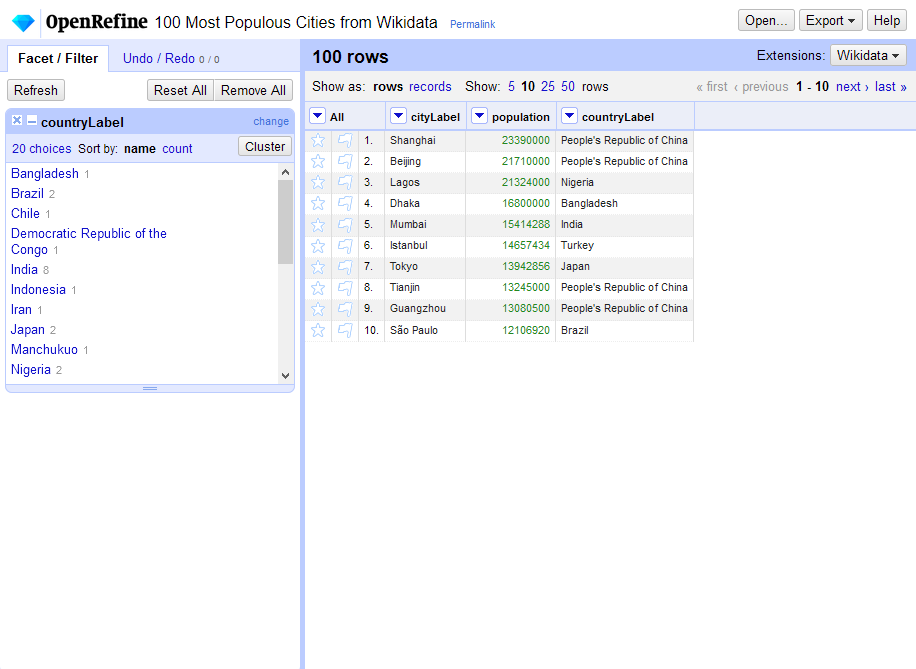
The project bar
The project bar runs across the very top of the project screen. It contains the the OpenRefine logo, the project title, and the project control buttons on the right side.
At any time you can close your current project and go back to the home screen by clicking on the OpenRefine logo. If you’d like to open another project in a new browser tab or window, you can right-click on the logo and use “Open in a new tab.” You will lose your current facets and view settings if you close your project (but data transformations will be saved in the History of the project).
Don’t click the “back” button on your browser - it will likely close your current project and you will lose your facets and view settings.
You can rename a project at any time by clicking inside the project title, which will turn into a text field. Project names don’t have to be unique, as OpenRefine organizes them based on a unique identifier behind the scenes.
The allows you to return to a project at a specific view state - that is, with facets and filters applied. The can help you pick up where you left off if you have to close your project while working with facets and filters. It puts view-specific information directly into the URL: clicking on it will load this current-view URL in the existing tab. You can right-click and copy the URL to copy the current view state to your clipboard, without refreshing the tab you’re using.
The button will open up a new browser tab showing the screen. From here you can change settings, start a new project, or open an existing project.
is a dropdown menu that allows you to pick a format for exporting a dataset. Many of the export options will only export rows and records that are currently visible - the currently selected facets and filters, not the total data in the project.
will open up a new browser tab and bring you to this user manual on the web.
The grid header
The grid header sits below the project bar and above the project grid (where the data of your project is displayed). The grid header will tell you the total number of rows or records in your project, and indicate whether you are in rows or records mode.
It will also tell you if you’re currently looking at a select number of rows via facets or filtering, rather than the entire dataset, by displaying either, for example, “180 rows” or “67 matching rows (180 total).”
Directly below the row number, you have the ability to switch between row mode and records mode. OpenRefine stores projects persistently in one of the two modes, and displays your data as records by default if you are.
To the right of the rows/records selection is the array of options for how many rows/records to view on screen at one time. At the far right of the screen you can navigate through your entire dataset one page at a time.
Extensions
The dropdown offers you options for extending your data - most commonly by uploading your edited statements to Wikidata, or by importing or exporting schema. You can learn more about these functions on the Wikibase section. Other extensions may also add functions to this dropdown menu.
The grid
The area of the project screen that displays your dataset is called the “grid” (or the “data grid,” or the “project grid”). The grid presents data in a tabular format, which may look like a normal spreadsheet program to you.
Columns widths are automatically set based on their contents; some column headers may be cut off, but can be viewed by mousing over the headers.
In each column header you will see a small arrow. Clicking on this arrow brings up a dropdown menu containing column-specific data exploration and transformation options. You will learn about each of these options in the Exploring data and Transforming data sections.
The first column in every project will always be , which contains options to flag, star, and do non-column-specific operations. The column is also where rows/records are numbered. Numbering shows the permanent order of rows and records; a temporary sorting or facet may reorder the rows or show a limited set, but numbering will show you the original identifiers unless you make a permanent change.
The project grid may display with both vertical and horizontal scrolling, depending on the number and width of columns, and the number of rows/records displayed. You can control the display of the project grid by using Sort and View options.
Mousing over individual cells will allow you to edit cells individually.
Facet/Filter
The Facet/Filter tab is one of the main ways of exploring your data: displaying the patterns and trends in your data, and helping you narrow your focus and modify that data. Facets and filters are explained more in Exploring data.
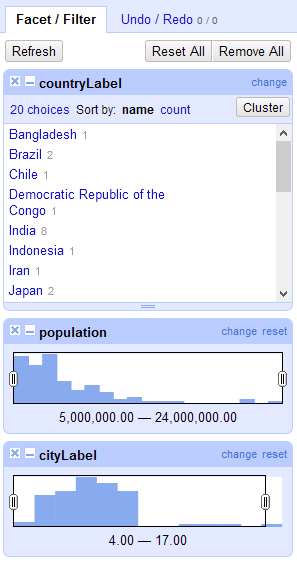
In the tab, you will see three buttons: , , and .
Refreshing your facets will ensure you are looking at the latest information about each facet, for example if you have changed the counts or eliminated some options.
Resetting your facets will remove any inclusion or exclusion you may have set - the facet options will stay in the sidebar, but your view settings will be undone.
Removing your facets will clear out the sidebar entirely. If you have written custom facets using expressions, these will be lost.
You can preserve your facets and filters for future use by copying a .
History (Undo/Redo)
In OpenRefine, any activity that changes the data can be undone. Changes are tracked from the very beginning, when a project is first created. The change history of each project is saved with the project's data, so quitting OpenRefine does not erase the steps you've taken. When you restart OpenRefine, you can view and undo changes that you made before you quit OpenRefine. OpenRefine autosaves your actions every five minutes by default, and when you close OpenRefine properly (using Ctrl + C). You can change this interval.
Project history gets saved when you export a project archive, and restored when you import that archive to a new installation of OpenRefine.
 tab with 13 steps.")
When you click on the Undo / Redo tab in the sidebar of any project, that project’s history is shown as a list of changes in order, with the first “change” being the action of creating the project itself. (That first change, indexed as step zero, cannot be undone.) Here is a sample history with 3 changes:
0. Create project
1. Remove 7 rows
2. Create new column Last Name based on column Name with grel:value.split(" ")
3. Split 230 cell(s) in column Address into several columns by separator
The current state of the project is highlighted with a dark blue background. If you move back and forth on the timeline you will see the current state become highlighted, while the actions that came after that state will be grayed out.
To revert your data back to an earlier state, simply click on the last action in the timeline you want to keep. In the example above, if we keep the removal of 7 rows but revert everything we did after that, then click on “Remove 7 rows.” The last 2 changes will be undone, in order to bring the project back to state #1.
In this example, changes #2 and #3 will now be grayed out. You can redo a change by clicking on it in the history - everything up to and including it will be redone.
If you have moved back one or more states, and then you perform a new operation on your data, the later actions (everything that’s greyed out) will be erased and cannot be re-applied.
The Undo/Redo tab will indicate which step you’re on, and if you’re about to risk erasing work - by saying something like “4/5" or “1/7” at the end.
Reusing operations
Operations that you perform in OpenRefine can be reused. For example, a formula you wrote inside one project can be copied and applied to another project later.
To reuse one or more operations, first extract it from the project where it was first applied. Click to the Undo/Redo tab and click . This brings up a box that lists all operations up to the current state (it does not show undone operations). Select the operation or operations you want to extract using the checkboxes on the left, and they will be encoded as JSON on the right. Copy that JSON to the clipboard.
Move to the second project, go to the Undo/Redo tab, click and paste in that JSON.
Not all operations can be extracted. Edits to a single cell, for example, can’t be replicated.
Advanced OpenRefine uses
Running OpenRefine's Linux version on a Mac
You can run OpenRefine from the command line in Mac by using the Linux installation package. We do not promise support for this method. Follow the instructions in the Linux section.
Running as a server
Please note that if your machine has an external IP (is exposed to the Internet), you should not do this, or should protect it behind a proxy or firewall, such as nginx. Proceed at your own risk.
By default (and for security reasons), OpenRefine only listens to TCP requests coming from localhost (127.0.0.1) on port 3333. If you want to share your OpenRefine instance with colleagues and respond to TCP requests to any IP address of the machine, start it from the command line like this:
./refine -i 0.0.0.0
or set this option in refine.ini:
REFINE_HOST=0.0.0.0
or set this JVM option:
-Drefine.host=0.0.0.0
On Mac, you can add a specific entry to the Info.plist file located within the app bundle (/Applications/OpenRefine.app/Contents/Info.plist):
<key>JVMOptions</key>
<array>
<string>-Drefine.host=0.0.0.0</string>
…
</array>
OpenRefine has no built-in security or version control for multi-user scenarios. OpenRefine has a single data model that is not shared, so there is a risk of data operations being overwritten by other users. Care must be taken by users.
Automating OpenRefine
Some users may wish to employ OpenRefine for batch processing as part of a larger automated pipeline. Not all OpenRefine features can work without human supervision and advancement (such as clustering), but many data transformation tasks can be automated.
The following are all third-party extensions and code; the OpenRefine team does not maintain them and cannot guarantee that any of them work.
Some examples:
- This project allows OpenRefine to be run from the command line using operations saved in a JSON file: OpenRefine batch processing
- A Python project for applying a JSON file of operations to a data file, outputting the new file, and deleting the temporary project, written by David Huynh and Max Ogden: Python client library for Google Refine
- And the same in Ruby: Refine-Ruby
- Another Python client library, by Paul Makepeace: OpenRefine Python Client Library
To look for other instances, search our former Google Groups for users and for developers, where these projects were originally posted.