Reconciling
Overview
Reconciliation is the process of matching your dataset with that of an external source. Datasets for comparison might be produced by libraries, archives, museums, academic organizations, scientific institutions, non-profits, or interest groups. You can also reconcile against user-edited data on Wikidata or other Wikibase instances, or reconcile against a local dataset that you yourself supply.
To reconcile your OpenRefine project against an external dataset, that dataset must offer a web service that conforms to the Reconciliation Service API standards.
You may wish to reconcile in order to:
- fix spelling or variations in proper names
- clean up manually-entered subject headings against authorities such as the Library of Congress Subject Headings (LCSH)
- link your data to an existing dataset
- add to an editable platform such as Wikidata
- or see whether entities in your project appear in some specific list, such as the Panama Papers.
Reconciliation is semi-automated: OpenRefine matches your cell values to the reconciliation information as best it can, but human judgment is required to review and approve the results. Reconciling happens by default through string searching, so typos, whitespace, and extraneous characters will have an effect on the results. You may wish to clean and cluster your data before reconciliaton.
We recommend planning your reconciliation operations as iterative: reconcile multiple times with different settings, and with different subgroups of your data.
Sources
Start with this current list of reconcilable authorities, which includes instructions for adding new services via Wikidata editing if you have one to add.
OpenRefine maintains a further list of sources on the wiki, which can be edited by anyone. This list includes ways that you can reconcile against a local dataset.
Other services may exist that are not yet listed in these two places: for example, the 310 datasets hosted by the Organized Crime and Corruption Reporting Project (OCCRP) each have their own reconciliation URL, or you can reconcile against their entire database with the URL shared on the reconciliation API list. For another example, you can reconcile against the entire Virtual International Authority File (VIAF) dataset, or only the contributions from certain institutions. Search online to see if the authority you wish to reconcile against has an available service, or whether you can download a copy to reconcile against locally.
OpenRefine includes Wikidata reconciliation in the installation package - see the Wikibase page for more information particular to that service. Extensions can add reconciliation services, and can also add enhanced reconciliation capacities. Check the list of extensions on the Downloads page for more information.
Each source will have its own documentation on how it provides reconciliation. The table on the reconciliation API list indicates whether your chosen service supports the features described below. Refer to the service's documentation if you have questions about its behaviors and which OpenRefine features it supports.
In addition to the reconciliation services mentioned above, you may also choose to build your own service. You can either start from scratch using the API specification or use one of the frameworks mentioned in the Reconciliation census.
Of particular note is reconcile-csv which allows you to build a reconciliation service from a simple CSV file. Thus if you wanted to reconcile one OpenRefine project against another, you'd simply need to export the target project as a CSV, point reconcile-csv at it and you're good to go. A somewhat newer port of this project written in Python can be found at csv-reconcile which is more configurable and defaults to parsing tab separated files for convenience.
Similiarly, you may choose to export some SPARQL output to a TSV to limit the scope of values you're reconciling against and/or for better peformance.
Getting started
Choose a column to reconcile and use its dropdown menu to select → . If you want to reconcile only some cells in that column, first use filters and facets to isolate them.
In the reconciliation window, you will see Wikidata offered as a default service. To add another service, click and paste in the URL of a service. You should see the name of the service appear in the list of if the URL is correct.
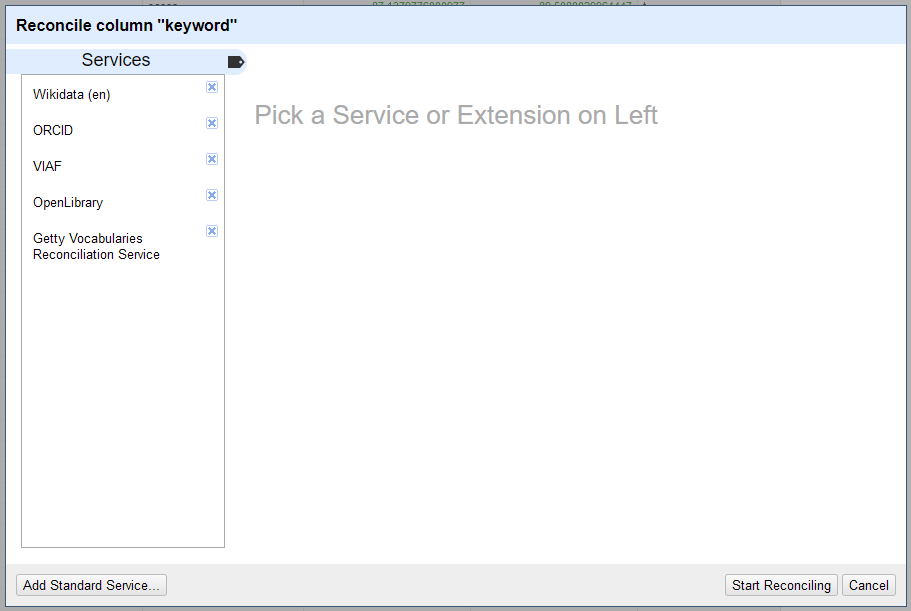
Once you select a service, your selected column may be sampled in order to suggest “types” (categories) to reconcile against. Other services will suggest their available types without sampling, and some services have no types.
For example, if you had a list of artists represented in a gallery collection, you could reconcile their names against the Getty Research Institute’s Union List of Artist Names (ULAN). The same Getty reconciliation URL will offer you ULAN, AAT (Art and Architecture Thesaurus), and TGN (Thesaurus of Geographic Names).
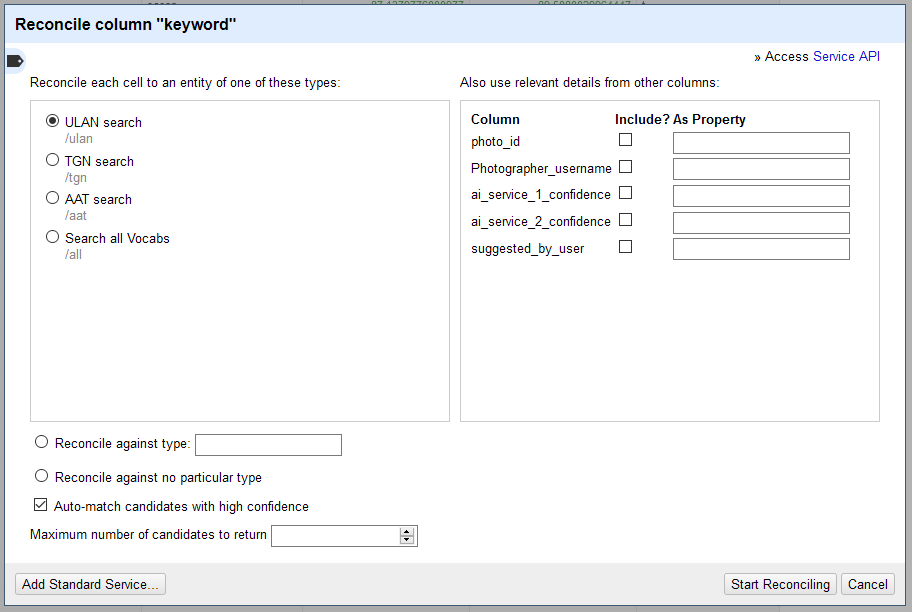
Refer to the documentation specific to the reconciliation service to learn whether types are offered, which types are offered, and which one is most appropriate for your column. You may wish to facet your data and reconcile batches against different types if available.
Reconciliation can be a time-consuming process, especially with large datasets. We suggest starting with a small test batch. There is no throttle (delay between requests) to set for the reconciliation process. The amount of time will vary for each service, and vary based on the options you select during the process.
When the process is done, you will see the reconciliation data in the cells. If the cell was successfully matched, it displays text as a single dark blue link. In this case, the reconciliation is confident that the match is correct, and you should not have to check it manually. If there is no clear match, one or more candidates are displayed, together with their reconciliation score, with the text in light blue links. You will need to select the correct one.
For each matching decision you make, you have two options: match this cell only (one checkmark), or also use the same identifier for all other cells containing the same original string (two checkmarks).
For services that offer the “preview entities” feature, you can hover your mouse over the suggestions to see more information about the candidates or matches. Each participating service (and each type) will deliver different structured data that may help you compare the candidates.
For example, the Getty ULAN shows an artist’s discipline, nationality, and birth and death years:
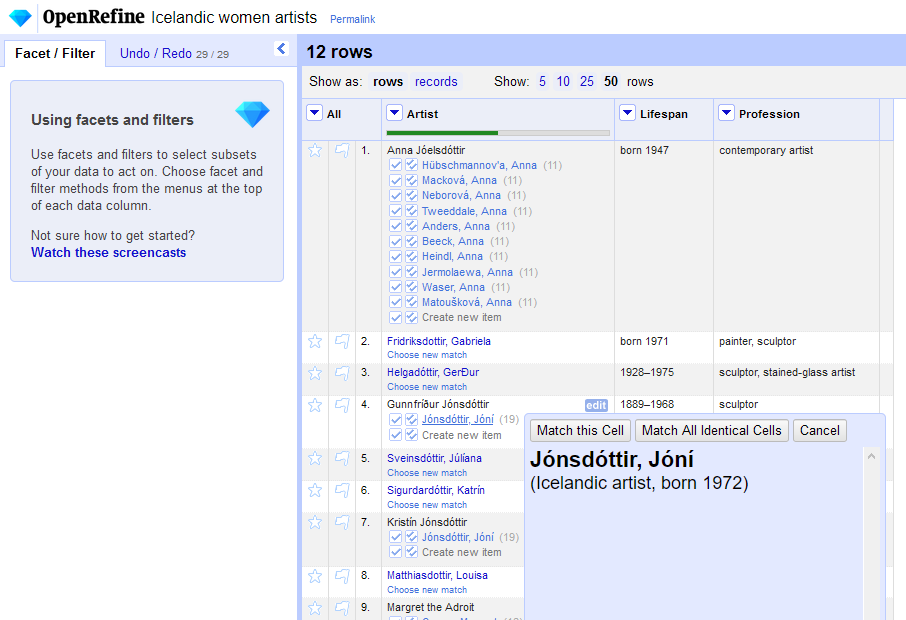
Hovering over the suggestion will also offer the two matching options as buttons.
For matched values (those appearing as dark blue links), the underlying cell value has not been altered - the cell is storing both the original string and the matched entity link at the same time. If you were to copy your column to a new column at this point using value, for example, the reconciliation data would not transfer - only the original strings. You can learn more about how OpenRefine stores different pieces of information in each cell in the Variables section specific to reconciliation data.
For each cell, you can manually “Create new item,” which will take the cell’s original value and apply it, as though it is a match. This will not become a dark blue link, because at this time there is nothing to link to: it is a draft entity stored only in your project. You can use this feature to prepare these entries for eventual upload to an editable service such as Wikibase, but most services do not yet support this feature.
Reconciliation facets
Under → there are a number of reconciliation-specific faceting options. OpenRefine automatically creates two facets when you reconcile some cells.
One is a numeric facet for “best candidate's score,” the range of reconciliation scores of only the best candidate of each cell. Higher scores mean better matches, although each service calculates scores differently and has a different range. You can facet for higher scores using the numeric facet, and then approve them all in bulk, by using → → .
There is also a “judgment” facet created, which lets you filter for the cells that haven't been matched (pick “none” in the facet). As you process each cell, its judgment changes from “none” to “matched” and it disappears from the view.
You can add other facets by selecting → on your reconciled column. You can facet by:
- your judgments (“matched,” or “none” for unreconciled cells, or “new” for entities you've created)
- the action you’ve performed on that cell (chosen a “single” match, or set a “mass” match, or no action, which appears as “unknown”)
- the timestamps on the edits you’ve made so far (these appear as millisecond counts since an arbitrary point: they can be sorted alphabetically to move forward and back in time).
You can facet only the best candidates for each cell, based on:
- the score (calculated based on each service's own methods)
- the edit distance (using the Levenshtein distance, a number based on how many single-character edits would be required to get your original value to the candidate value, with a larger value being a greater difference)
- the word similarity.
Word similarity is calculated as a percentage based on how many words (excluding stop words) in the original value match words in the candidate. For example, the value “Maria Luisa Zuloaga de Tovar” matched to the candidate “Palacios, Luisa Zuloaga de” results in a word similarity value of 0.6, or 60%, or 3 out of 5 words. Cells that are not yet matched to one candidate will show as 0.0).
You can also look at each best candidate’s:
- type (the ones you have selected in successive reconciliation attempts, or other types returned by the service based on the cell values)
- type match (“true” if you selected a type and it succeeded, “false” if you reconciled against no particular type, and “(no type)” if it didn’t reconcile)
- name match (“true” if you’ve matched, “false” if you haven’t yet chosen from the candidates, or “(unreconciled)” if it didn’t reconcile).
These facets are useful for doing successive reconciliation attempts, against different types, and with different supplementary information. The information represented by these facets are held in the cells themselves and can be called using the reconciliation variables available in expressions.
Reconciliation actions
You can use the → menu options to perform bulk changes (which will apply only to your currently viewed set of rows or records):
- (by highest score)
- (discard any suggested matches)
- (a new entity will be created for each unique string)
- (a specific item from the chosen service, via a search box; only works with services that support the “suggest entities” property)
- (reverts back to multiple candidates per cell, including cells that may have been auto-matched in the original reconciliation process)
- , reverting all cells back to their original values.
The other options available under are:
- (to an existing column: if the original values in your reconciliation column are identical to those in your chosen column, the matched and new cells will copy over; unmatched values will not change)
- (if you are reconciling with unique identifiers instead of by doing string searches)
- .
Reconciling with unique identifiers
Reconciliation services use unique identifiers for their entities. For example, the 14th Dalai Lama has the VIAF ID 38242123 and the Wikidata ID Q17293. You can supply your known identifiers in a column to immediately match with the known IDs from a reconciliation service in order to subsequently pull more data about them.
Select the column with unique known identifiers of a service and apply the operation → . If you use this operation on a column of known IDs, you will not have access to the usual reconciliation settings. Instead, this will bring up a dialog to select a service from the list of reconciliation services you have already added (to add a new service, open the window first).
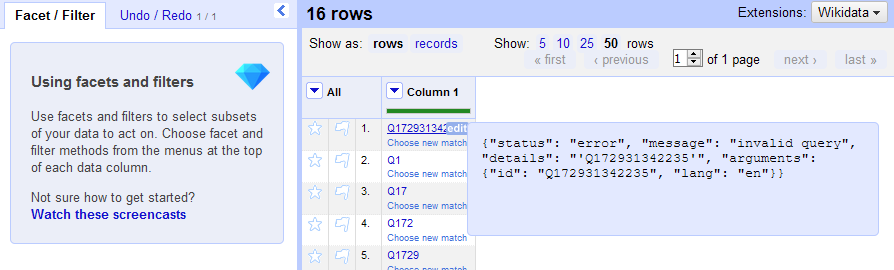
This operation is typically very fast and after it completes all cells will appear as dark blue “confirmed” matches.
You may get false positives (ex. the IDs no longer exist with the service), which you will need to hover over or click on to identify:
Reconciling by type
Reconciliation services, once added to OpenRefine, may suggest types from their databases. These types will usually be whatever the service specializes in: people, events, places, buildings, tools, plants, animals, organizations, etc.
Reconciling against a type may be faster and more accurate, but may result in fewer matches. Some services have hierarchical types (such as “mammal” as a subtype of “animal”). When you reconcile against a more specific type, unmatched values may fall back to the broader type; other services will not do this, so you may need to perform successive reconciliation attempts against different types. Refer to the documentation specific to the reconciliation service to learn more.
When you select a service from the list, OpenRefine will load some or all available types. Some services will sample the first ten rows of your column to suggest types (check the “Suggest types” column). You will see a service’s types in the reconciliation window:
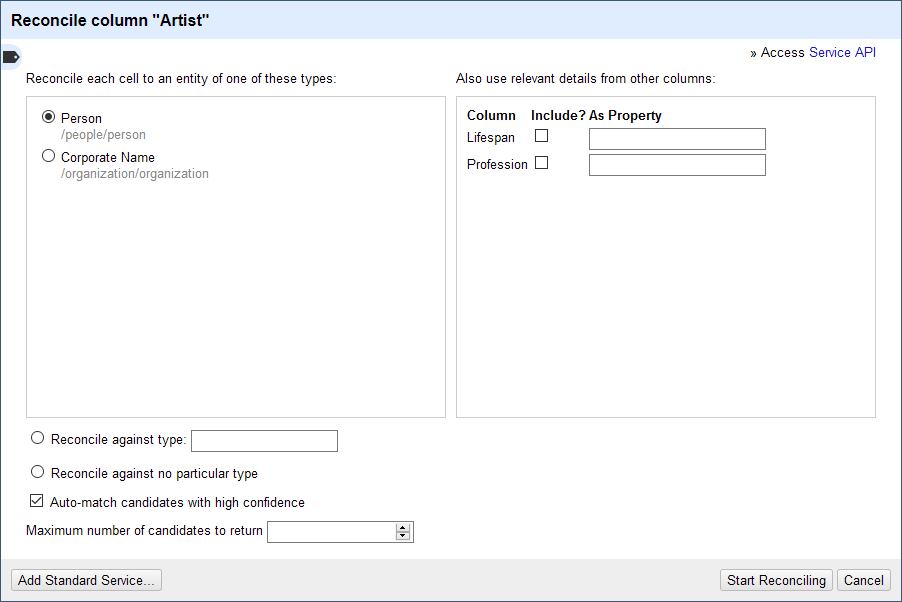
In this example, “Person” and “Corporate Name” are potential types offered by the reconciliation API for VIAF. You can also use the Reconcile against type: field to enter in another type that the service offers. When you start typing, this field may search and suggest existing types. For VIAF, you could enter “/book/book” if your column contained publications. You may need to enter the service's own strings precisely instead of attempting to search for a match.
Types are structured to fit their content: the Wikidata “human” type, for example, can include fields for birth and death dates, nationality, etc. The VIAF “person” type can include nationality and gender. You can use this to include more properties and find better matches.
If your column doesn’t fit one specific type offered, you can Reconcile against no particular type. This may take longer.
We recommend working in batches and reconciling against different types, moving from specific to broad. You can create a facet for facet to see which types are being represented. Some candidates may return more than one type, depending on the service. Types may appear in facets by their unique IDs, rather than by their semantic labels (for example, Q5 for “human” in Wikidata).
Reconciling with additional columns
Some of your cells may be ambiguous, in the sense that a string can point to more than one entity: there are dozens of places called “Paris” and many characters, people, and pieces of culture, too. Selecting non-geographic or more localized types can help narrow that down, but if your chosen service doesn't provide a useful type, you can include more properties that make it clear whether you're looking for Paris, France.
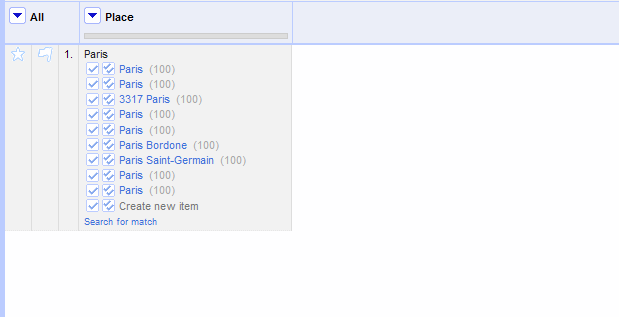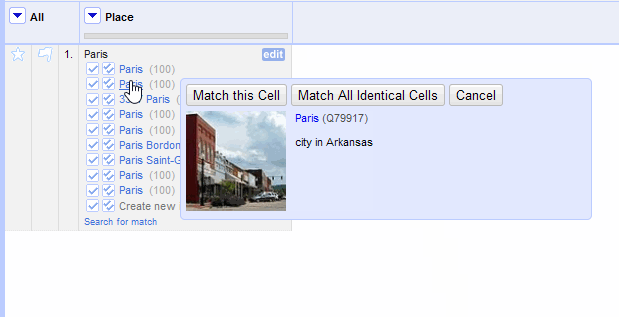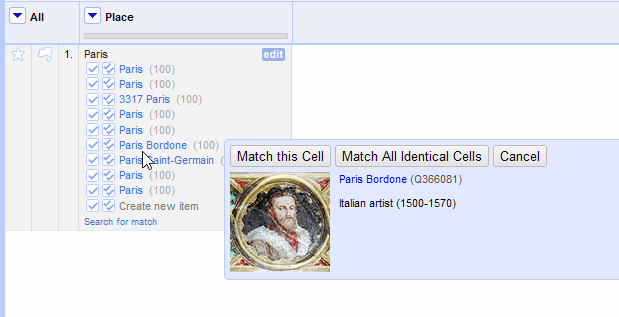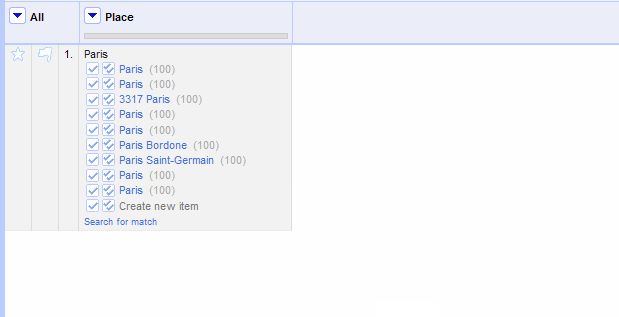
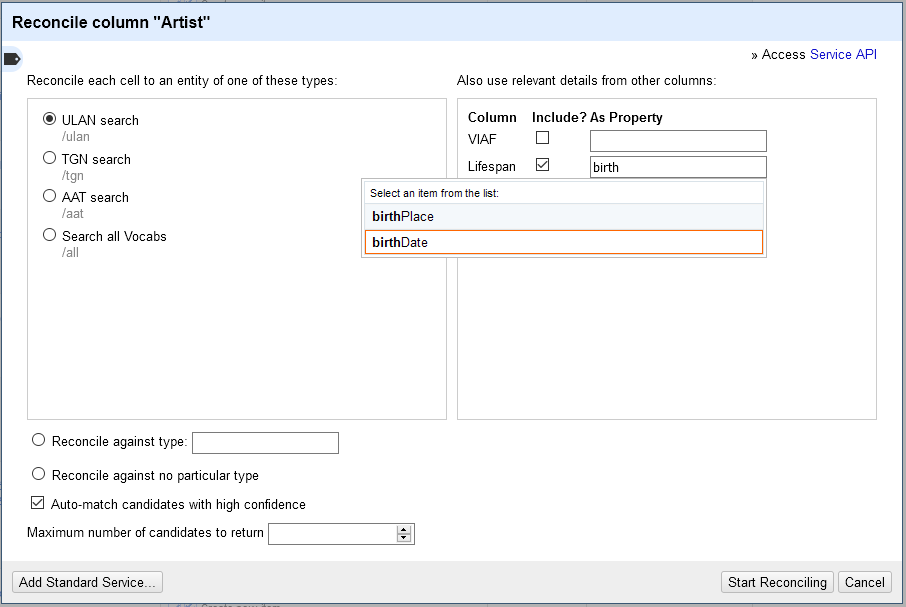
Including supplementary information can be useful, depending on the service (such as including birthdate information about each person you are trying to reconcile). You can re-reconcile unmatched cells with additional properties, in the right side of the window, under “Also use relevant details from other columns.” The column names in your project will appear in the reconciliation window, with an Include? checkbox next to each one.
Fill in the As Property field with the type of information you are including. When you start typing, potential fields may pop up (depending on the “suggest properties” feature), such as “birthDate” in the case of ULAN or “Geburtsdatum” in the case of Integrated Authority File (GND). Use the documentation for your chosen service to identify the fields in their terms.
Some services will not be able to search for the exact name of your desired As Property entry, but you can still manually supply the field name. Refer to the service to choose the most appropriate field, and make sure you enter it correctly.
Fetching more data
One reason to reconcile to some external service is that it allows you to pull data from that service into your OpenRefine project. There are three ways to do this:
- Add identifiers for your values
- Add columns from reconciled values
- Add column by fetching URLs.
Add entity identifiers column
Once you have selected matches for your cells, you can retrieve the unique identifiers for those cells and create a new column for these, with → . You will be asked to supply a column name. New items and other unmatched cells will generate null values in this column.
Add columns from reconciled values
If the reconciliation service supports data extension, then you can augment your reconciled data with new columns using → .
For example, if you have a column of chemical elements identified by name, you can fetch categorical information about them such as their atomic number and their element symbol:
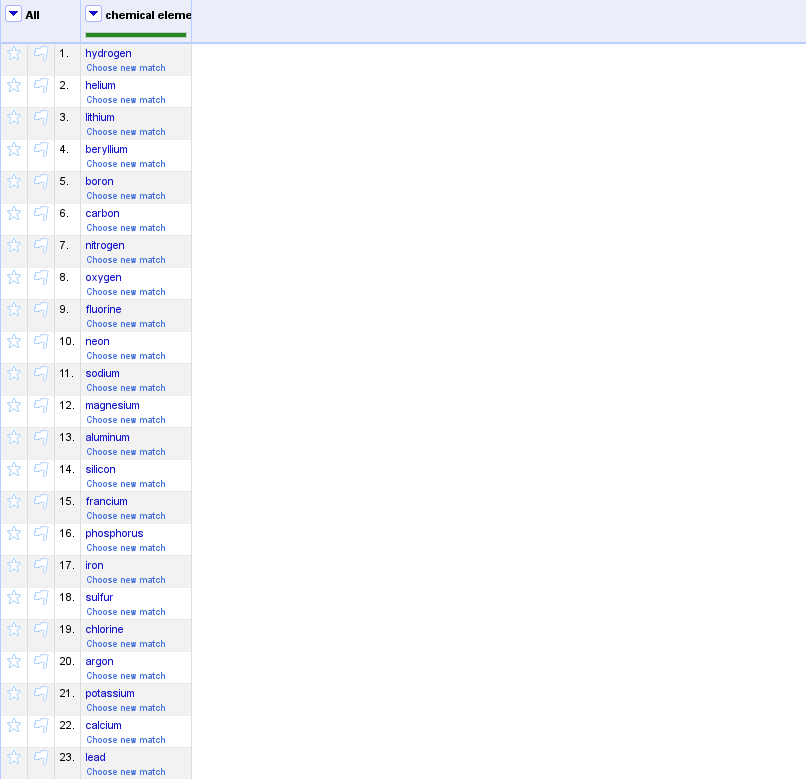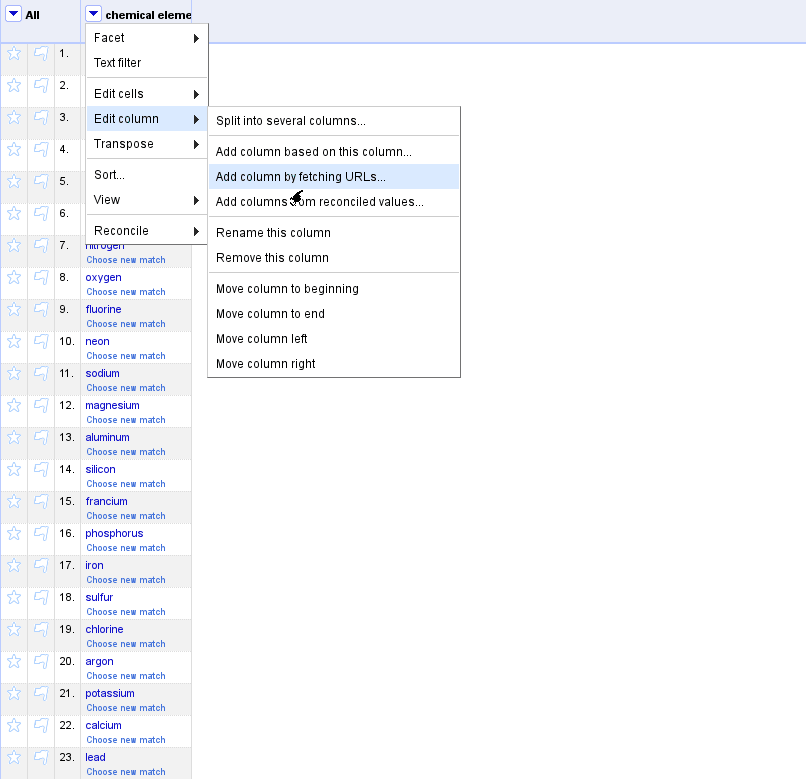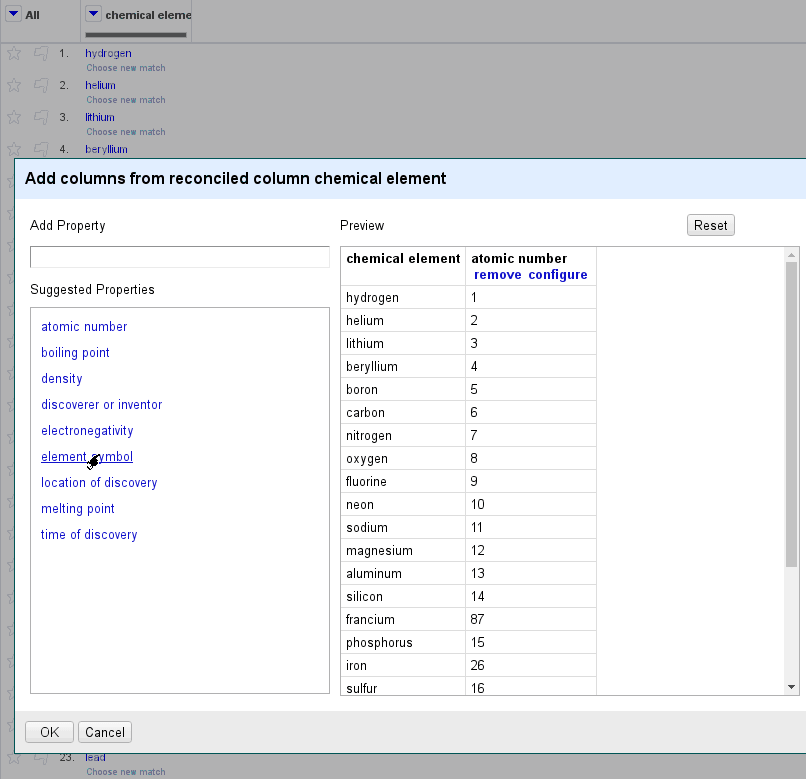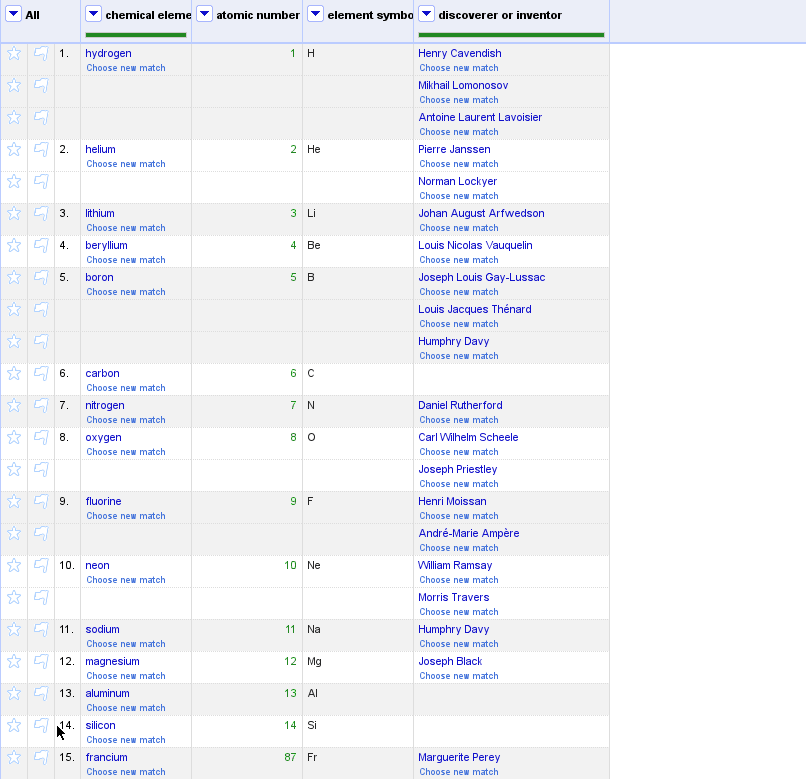
Once you have chosen reconciliation matches for your cells, selecting will bring up a window to choose which related information you’d like to import into new columns. You can manually enter desired properties, or select from a list of suggestions.
The quality of the suggested properties will depend on how you have reconciled your data beforehand: reconciling against a specific type will provide you with the associated properties of that type. For example, GND suggests elements about the “people” type after you've reconciled with it, such as their parents, native languages, children, etc.
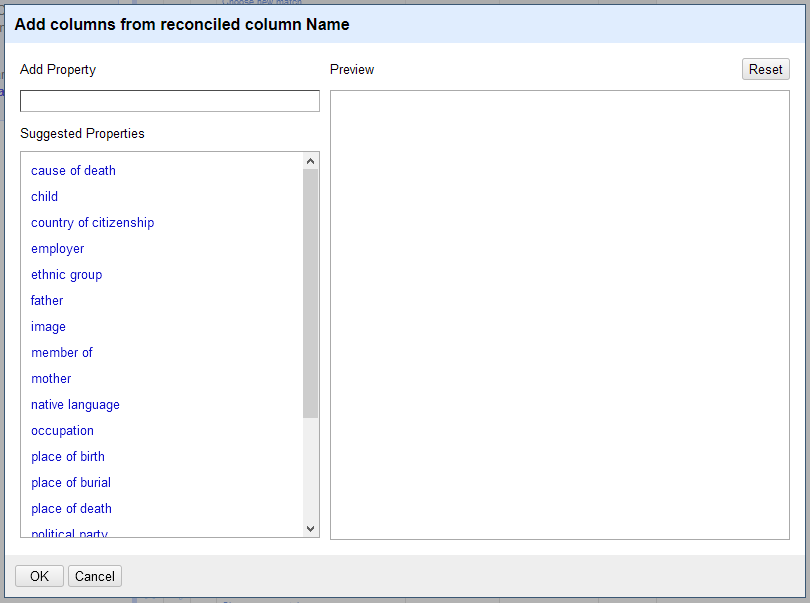
If you have left any values unreconciled in your column, you will see “<not reconciled>” in the preview. These will generate blank cells if you continue with the column addition process.
This process may pull more than one property per row in your data (such as multiple occupations), so you may need to switch into records mode after you've added columns.
Add columns by fetching URLs
If the reconciliation service cannot extend data, look for a generic web API for that data source, or a structured URL that points to their dataset entities via unique IDs (such as “https://viaf.org/viaf/000000”). You can use the → operation to call this API or URL with the IDs obtained from the reconciliation process. This will require using expressions.
You may not want to pull the entire HTML content of the pages at the ends of these URLs, so look to see whether the service offers a metadata endpoint, such as JSON-formatted data. You can either use a column of IDs, or you can pull the ID from each matched cell during the fetching process.
For example, if you have reconciled artists to the Getty's ULAN, and have their unique ULAN IDs as a column, you can generate a new column of JSON-formatted data by using and entering the GREL expression "http://vocab.getty.edu/" + value + ".json". For this service, the unique IDs are formatted “ulan/000000” and so the generated URLs look like “http://vocab.getty.edu/ulan/000000.json”.
Alternatively, you can insert the ID directly from the matched column's reconciliation variables, using a GREL expression like “http://vocab.getty.edu/” + cell.recon.match.id + “.json” instead.
Remember to set an appropriate throttle and to refer to the service documentation to ensure your compliance with their terms. See the section about this operation to learn more about the fetching process.
Keep all the suggestions made
To generate a list of each suggestion made, rather than only the best candidate, you can use a GREL expression. Go to → . To create a list of all the possible matches, use something like
forEach(cell.recon.candidates,c,c.name).join(", ")
To get the unique identifiers of these matches instead, use
forEach(cell.recon.candidates,c,c.id).join(", ")
This information is stored as a string, without any attached reconciliation information.
Writing reconciliation expressions
OpenRefine supplies a number of variables related specifically to reconciled values. These can be used in GREL and Jython expressions. For example, some of the reconciliation variables are:
cell.recon.match.idorcell.recon.match.namefor matched valuescell.recon.best.nameorcell.recon.best.idfor best-candidate valuescell.recon.candidatesfor all listed candidates of each cellcell.recon.judgment(the values used in the “judgment” facet)cell.recon.judgmentHistory(the values used in the “judgment action timestamp” facet)cell.recon.matched(a “true” or “false” value)
You can find out more in the reconciliaton variables section.
To make a copy of a reconciled column and all its contents (the entire recon object for each cell) into a new column, just use the GREL expression cell only when using → .
Exporting reconciled data
Once you have data that is reconciled to existing entities online, you may wish to export that data to a user-editable service such as Wikidata. See the section on uploading your edits to Wikidata or other Wikibase instances for more information, or the section on exporting to see other formats OpenRefine can produce.
You can share reconciled data in progress through a project export or import, with some preparation. The importing user needs to have the appropriate reconciliation services installed on their OpenRefine instance (by going to and clicking on ) in advance of opening the project, in order to use candidate and match links. Otherwise, the links will be broken and the user will need to add the reconciliation service and re-reconcile the columns in question. Wikidata reconciliation data can be shared more easily as the service comes bundled with OpenRefine.