Cell editing
Overview
OpenRefine offers a number of features to edit and improve the contents of cells automatically and efficiently.
One way of doing this is editing through a text facet. Once you have created a facet on a column, hover over the displayed results in the sidebar. Click on the small “edit” button that appears to the right of the facet, and type in a new value. This will apply to all the cells in the facet.
You can apply a text facet on numbers, boolean values, and dates, but if you edit a value it will be converted into the text data type (regardless of whether you edit a date into another correctly-formatted date, or a “true” value into “false”, etc.).
Transform
Select → to open up an expressions window. From here, you can apply expressions to your data. The simplest examples are GREL functions such as toUppercase() or toLowercase(), used in expressions as toUppercase(value) or toLowercase(value). When used on a column operation, value is the information in each cell in the selected column.
Use the preview to ensure your data is being transformed correctly.
You can also switch to the Undo / Redo tab inside the expressions window to reuse expressions you’ve already attempted in this project, whether they have been undone or not.
OpenRefine offers you some frequently-used transformations in the next menu option, . For more custom transforms, read up on expressions.
Common transforms
Trim leading and trailing whitespace
Often cell contents that should be identical, and look identical, are different because of space or line-break characters that are invisible to users. This function will get rid of any characters that sit before or after visible text characters.
Collapse consecutive whitespace
You may find that some text cells contain what look like spaces but are actually tabs, or contain multiple spaces in a row. This function will remove all space characters that sit in sequence and replace them with a single space.
Unescape HTML
Your data may come from an HTML-formatted source that expresses some characters through references (such as “ ” for a space, or “%u0107” for a ć) instead of the actual Unicode characters. You can use the “unescape HTML entities” transform to look for these codes and replace them with the characters they represent. For other formatting that needs to be escaped, try a custom transformation with escape().
Replace smart quotes with ASCII
Smart quotes (or curly quotes) recognize whether they come at the beginning or end of a string, and will generate an “open” quote (“) and a “close” quote (”). These characters are not ASCII-compliant (though they are UTF8-compliant) so you can use this tranform to replace them with a straight double quote character (") instead.
Case transforms
You can transform an entire column of text into UPPERCASE, lowercase, or Title Case using these three options. This can be useful if you are planning to do textual analysis and wish to avoid case-sensitivity (which some functions are) causing problems in your analysis. Consider also using a custom facet to temporarily modify cases instead of this permanent operation if appropriate.
Data-type transforms
As detailed in Data types, OpenRefine recognizes different data types: string, number, boolean, and date. When you use these transforms, OpenRefine will check to see if the given values can be converted, then both transform the data in the cells (such as “3” as a text string to “3” as a number) and convert the data type on each successfully transformed cell. Cells that cannot be transformed will output the original value and maintain their original data type.
Be aware that dates may require manual intervention to transform successfully: see the section on Dates for more information.
Because these common transforms do not offer the ability to output an error instead of the original cell contents, be careful to look for unconverted and untransformed values. You will see a yellow alert at the top of screen that will tell you how many cells were converted - if this number does not match your current row set, you will need to look for and manually correct the remaining cells. Also consider faceting by data type, with the GREL function type().
You can also convert cells into null values or empty strings. This can be useful if you wish to, for example, erase duplicates that you have identified and are analyzing as a subset.
Fill down and blank down
Fill down and blank down are two functions most frequently used when encountering data organized into records - that is, multiple rows associated with one specific entity.
If you receive information in rows mode and want to convert it to records mode, the easiest way is to sort your first column by the value that you want to use as a unique records key, make that sorting permanent, then blank down all the duplicates in that column. OpenRefine will retain the first unique value and erase the rest. Then you can switch from “Show as rows” to “Show as records” and OpenRefine will associate rows to each other based on the remaining values in the first column.
Be careful that your data is sorted properly before you begin blanking down - not just the first column but other columns you may want to have in a certain order. For example, you may have multiple identical entries in the first column, one with a value in the second column and one with an empty cell in the second column. In this case you want the row with the second-column value to come first, so that you can clean up empty rows later, once you blank down.
If, conversely, you’ve received data with empty cells because it was already in something akin to records mode, you can fill down information to the rest of the rows. This will duplicate whatever value exists in the topmost cell with a value: if the first row in the record is blank, it will take information from the next cell, or the cell after that, until it finds a value. The blank cells above this will remain blank.
Split multi-valued cells
Splitting cells with more than one value in them is a common way to get your data from single rows into multi-row records. Survey data, for example, frequently allows respondents to “Select all that apply,” or an inventory list might have items filed under more than one category.
You can split a column based on any character or series of characters you input, such as a semi-colon (;) or a slash (/). The default is a comma. Splitting based on a separator will remove the separator characters, so you may wish to include a space with your separator (; ) if it exists in your data.
You can use expressions to design the point at which a cell should split itself into two or more rows. This can be used to identify special characters or create more advanced evaluations. You can split on a line-break by entering \n and checking the “regular expression” checkbox.
Regular expressions can be useful if the split is not straightforward: say, if a capital letter ([A-Z]) indicates the beginning of a new string, or if you need to not always split on a character that appears in both the strings and as a separator. Remember that this will remove all the matching characters.
You can also split based on the lengths of the strings you expect to find. This can be useful if you have predictable data in the cells: for example, a 10-digit phone number, followed by a space, followed by another 10-digit phone number. Any characters past the explicit length you’ve specified will be discarded: if you split by “11, 10” any characters that may come after the 21st character will disappear. If some cells only have one phone number, you will end up with blank rows.
If you have data that should be split into multiple columns instead of multiple rows, see Split into several columns.
Join multi-valued cells
Joining will reverse the “split multi-valued cells” operation, or join up information from multiple rows into one row. All the strings will be compressed into the topmost cell in the record, in the order they appear. A window will appear where you can set the separator; the default is a comma and a space (, ). This separator is optional. We suggest the separator | as a sufficiently rare character.
Cluster and edit
Creating a facet on a column is a great way to look for inconsistencies in your data; clustering is a great way to fix those inconsistencies. Clustering uses a variety of comparison methods to find text entries that are similar but not exact, then shares those results with you so that you can merge the cells that should match. Where editing a single cell or text facet at a time can be time-consuming and difficult, clustering is quick and streamlined.
Clustering always requires the user to approve each suggested edit - it will display values it thinks are variations on the same thing, and you can select which version to keep and apply across all the matching cells (or type in your own version).
OpenRefine will do a number of cleanup operations behind the scenes in order to do its analysis, but only the merges you approve will modify your data. Understanding those different behind-the-scenes cleanups can help you choose which clustering method will be more accurate and effective.
You can start the process in two ways: using the dropdown menu on your column, select → ; or create a text facet and then press the “Cluster” button that appears in the facet box.
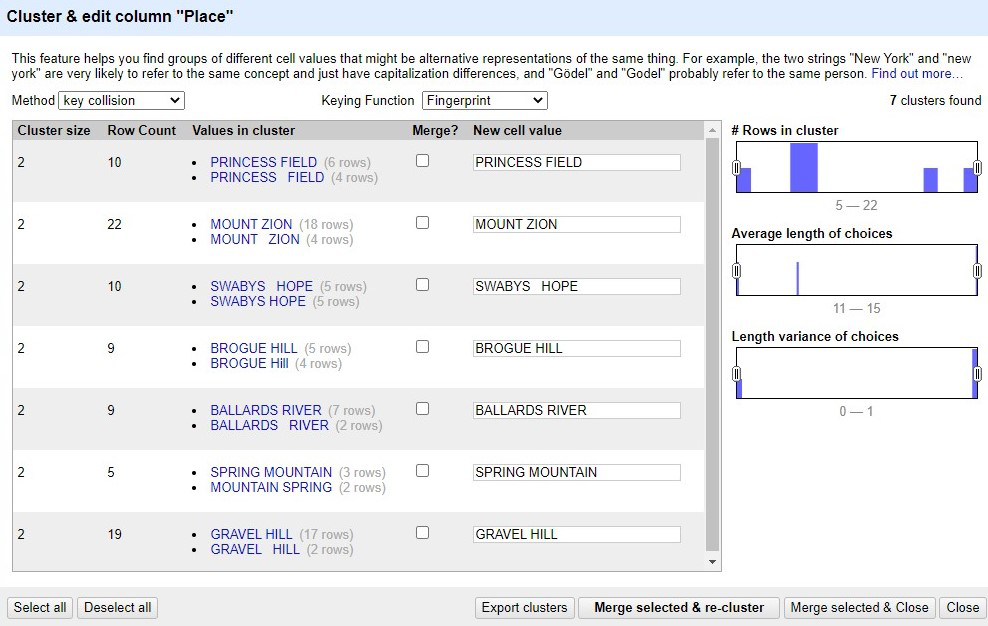
The clustering pop-up window will take a small amount of time to analyze your column, and then make some suggestions based on the clustering method currently active.
For each cluster identified, you can pick one of the existing values to apply to all cells, or manually type in a new value in the text box. And, of course, you can choose not to cluster them at all. OpenRefine will keep analyzing every time you make a change, with , and you can work through all the methods this way.
You can also export the currently identified clusters as a JSON file, or close the window with or without applying your changes. You can also use the histograms on the right to narrow down to, for example, clusters with lots of matching rows, or clusters of long or short values.
Clustering methods
You don’t need to understand the details behind each clustering method to apply them successfully to your data.
The order in which these methods are presented in the interface and on this page is the order we recommend - starting with the most strict rules and moving to the laxest, which require more human supervision to apply correctly.
The clustering pop-up window offers you two categories of clustering methods: 6 different key collision clustering methods and 2 nearest neighbour clustering methods.
-
The Key Collision category is itself subcategorized by phonetic or not-phonetic clustering.
Key Collision
Key collisions are very fast and can process millions of cells in seconds:
Fingerprinting is the least likely to produce false positives, so it’s a good place to start. It does the same kind of data cleaning behind the scenes that you might think to do manually:
- fix whitespace into single spaces
- put all uppercase letters into lowercase
- discard punctuation
- remove diacritics (e.g. accents) from characters
- split up all strings (words) and sort them alphabetically (so “Zhenyi, Wang” becomes “wang zhenyi”).
For an in-depth understanding of fingerprinting, check this document
N-gram fingerprinting allows you to set the n value to whatever number you’d like and will create n-grams of n size (after doing some cleaning), alphabetize them, then join them back together into a fingerprint.
For example, a 1-gram fingerprint will simply organize all the letters in the cell into alphabetical order - by creating segments one character in length. A 2-gram fingerprint will find all the two-character segments, remove duplicates, alphabetize them, and join them back together (for example, “banana” generates “ba an na an na,” which becomes “anbana”).
This can help match cells that have typos, or incorrect spaces (such as matching “lookout” and “look out,” which fingerprinting itself won’t identify because it separates words). The higher the n value, the fewer clusters will be identified. With 1-grams, keep an eye out for mismatched values that are near-anagrams of each other (such as “Wellington” and “Elgin Town”).
For an in-depth understanding of N-gram fingerprinting, check this document
The next four methods are phonetic algorithms: they identify letters that sound the same when pronounced out loud, and assess text values based on that (such as knowing that a word with an “S” might be a mistype of a word with a “Z”). They are great for spotting mistakes made by not knowing the spelling of a word or name after hearing it spoken aloud.
Metaphone3 fingerprinting is an English-language phonetic algorithm. For example, “Reuben Gevorkiantz” and “Ruben Gevorkyants” share the same phonetic fingerprint in English.
Cologne fingerprinting is another phonetic algorithm, but for German pronunciation.
Daitch-Mokotoff is a phonetic algorithm for Slavic and Yiddish words, especially names.
Baider-Morse is a version of Daitch-Mokotoff that is slightly more strict.
Regardless of the language of your data, applying each of them might find different potential matches: for example, Metaphone clusters “Cornwall” and “Corn Hill” and “Green Hill,” while Cologne clusters “Greenvale” and “Granville” and “Cornwall” and “Green Wall.”
For an in-depth understanding of phonetics, check this document
Nearest Neighbor
Nearest Neighbor clustering methods are slower than key collision methods.
They allow the user to set a radius - a threshold for matching or not matching. OpenRefine uses a “blocking” method first, which sorts values based on whether they have a certain amount of similarity (the default is “6” for a six-character string of identical characters) and then runs the nearest-neighbor operations on those sorted groups.
We recommend setting the block number to at least 3, and then increasing it if you need to be more strict (for example, if every value with “river” is being matched, you should increase it to 6 or more).
Note that bigger block values will take much longer to process, while smaller blocks may miss matches. Increasing the radius will make the matches more lax, as bigger differences will be clustered.
Levenshtein distance counts the number of edits required to make one value perfectly match another. As in the key collision methods above, it will do things like change uppercase to lowercase, fix whitespace, change special characters, etc. Each character that gets changed counts as 1 “distance.” “New York” and “newyork” have an edit distance value of 3 (“N” to “n”; “Y” to “y”; remove the space).
It can do relatively advanced edits, such as understanding the distance between “M. Makeba” and “Miriam Makeba” (5), but it may create false positives if these distances are greater than other, simpler transformations (such as the one-character distance to “B. Makeba,” another person entirely).
PPM (Prediction by Partial Matching)
PPM (Prediction by Partial Matching) uses compression to see whether two values are similar or different. In practice, this method is very lax even for small radius values and tends to generate many false positives, but because it operates at a sub-character level it is capable of finding substructures that are not easily identifiable by distances that work at the character level. So it should be used as a “last resort” clustering method. It is also more effective on longer strings than on shorter ones.
For more of the theory behind clustering, see Clustering In Depth.
Replace
OpenRefine provides a find/replace function for you to edit your data. Selecting → will bring up a simple window where you can input a string to search and a string to replace it with. You can set case-sensitivity, and set it to only select whole words, defined by a string with spaces or punctuation around it (to prevent, for example, “house” selecting the “house” part of “doghouse”). You can use regular expressions in this field. You may wish to preview the results of this operation by testing it with a Text filter first.
You can also perform a sort of find/replace operation by editing one cell, and selecting “apply to all identical cells.”
Edit one cell at a time
You can edit individual cells by hovering your mouse over that cell. You should see a tiny blue link labeled “edit.” Click it to edit the cell. That pops up a window with a bigger text field for you to edit. You can change the data type of that cell, and you can apply these changes to all identical cells (in the same column), using this pop-up window.
You will likely want to avoid doing this except in rare cases - the more efficient means of improving your data will be through automated and bulk operations.